
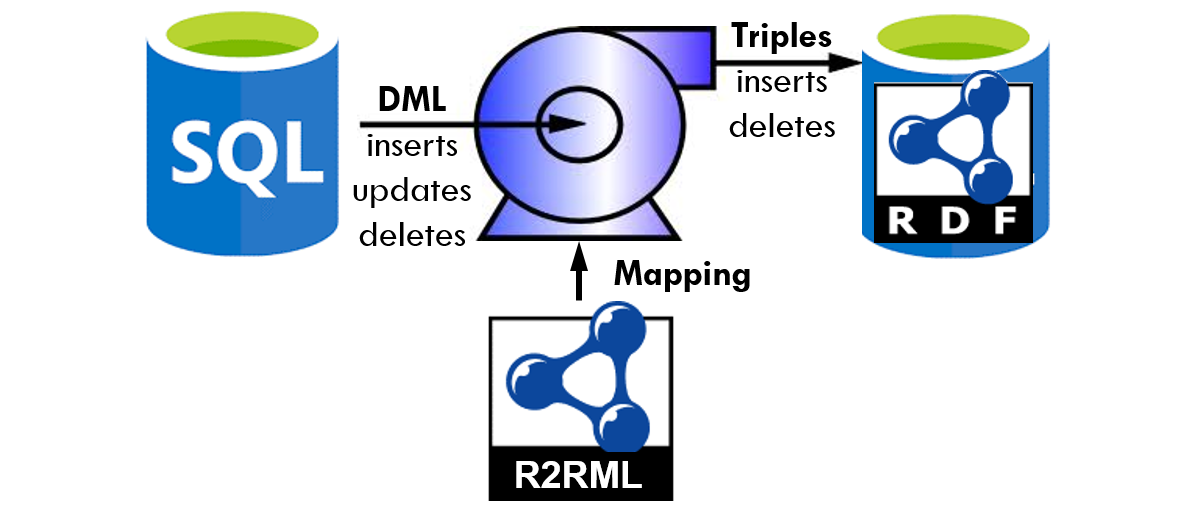
SQL2RDF ‘incremental materialization’ uses a stream of source data changes (DML) and transforms them to the corresponding changes (inserts, deletes) in the triple store ensuring concurrency between RDBMS and triplestore. SQL2RDF incremental materialization is based on the same R2RML mapping used for virtualization (Ontop), and (Capsenta), and materialization (In4mium, and R2RML Parser) thus does not incur an additional configuration maintenance problem.
Mapping an existing RDBMS to RDF has become an increasingly popular way of accessing data when the system-of-record is not, or cannot be, in a RDF database. Despite its attractiveness, virtualization is not always possible for various reasons such as performance, the need for full SPARQL 1.1 support, the need to reason over the virtualized as well as other materialized data, etc. However materialization of an existing RDBMS to RDF is also not an ideal alternative. Reasons include the inevitable lack of concurrency between the system-of-record and the RDF.
Thus incremental materialization provides an alternative between virtualization and materialization, offering:
- Easy ETL of source RDB as no additional configuration required other than the sameR2RMLrequired for virtualization or bulk materialization.
- Improved concurrency of data compared with materialization.
- Significantly less computational overhead than a full materialization of the source data.
- Improved query performance compared with virtualization especially when reasoning is required.
- Compatibility with R2RML thus reducing configuration maintenance.
- Supports insert, update, and delete changes on the source RDBMS.
- Source transactions can be batched, and the changes to the triplestore are part of a single transaction that can be rolled back in the event of a problem.
- Supports change logging so that committed changes can be rolled back.
RDBMS to RDF Mapping
Mapping an existing RDBMS to RDF has become an increasingly popular way of accessing data when the system-of-record is not, or cannot be, in a RDF database.
Mapping Models
Tools such as D2R, Capsenta, or Ontop provide a SPARQL endpoint to an underlying RDBMSs. In provisioning such an endpoint, a mapping needs to be created between the RDBMS schema and the required RDF ontology. Several formats are possible for this mapping model:
- D2RQ: the mapping language used by D2R
- OBDA: Ontology-Based Data Access, the mapping language used by Ontop, but which is convertible to R2RMLwhen using the Protégé plugin for Ontop
- R2RML: the current de-facto standard mapping language which supersedes D2RQ.
Virtualization versus Materialization
Given a mapping between a RDBMS and a RDF ontology, one has the option of virtualized or materialized access to the underlying data in the RDBMS:
- Virtualization: allows access to the underlying RDMS via a SQARQL endpoint as if that data is stored in a triple-store. The SPARQL endpoint therefore interprets any SPARQL requests, converting them to the equivalent SQL to be executed. The conversion from the SPARQL to the corresponding SQL requires the mapping model referred to above: D2RQ, OBDA or R2RML.
- Materialization: requires that the underlying RDBMS data is converted to RDF and inserted into the triple store from where queries can be provisioned using the SPARQL endpoint associated with the triple store
Which technique is better depends largely on the particular circumstances of the installation. The advantages and disadvantages of each techniques are summarized below:
- Virtualization:
- Pros:
- Avoids any replication of the underlying data.
- Changes to the underlying RDBMS data becomes immediately available to the user of the SPARQL endpoint.
- Changes to the mapping model do not require a complete rebuild of the replicated data in the triple store.
- The virtualized triples will always be 100% concurrent with the RDBMS data (unless the virtualization is against a materialized view of the underlying data).
- Cons:
- Requires access to the operational data in the RDBMS, which might be contrary to the policies in place for ad hoc access to an operational data store.
- Requires the definition of, and sustainment of, the mapping model which can easily run to 100’s of individual mapping terms.
- The SPARQL endpoints provided by these virtualizations do not (yet) fully support SPARQL1.1.
- Any inferencing across data that is both in the RDBMS and another triple store could create performance issues.
- Forward chaining would require that inferred data be recreated whenever the underlying RDBMS changes.
- Backward chaining would rely on the availability of mapping rules created by the inference engine.
- Performance of the resulting SQL query assumes that the RDBMS has appropriate indices. If not it can be difficult in practice, due to operational policies rather than technical challenges, to add indices just to support the SPARQL endpoint.
- Pros:
- Materialization:
- Pros:
- Performance will not be inhibited by the need to infer the SQL from the SPARQL query.
- Invariably the triple store will fully support SPARQL1.1, such as property path queries.
- Inferencing performance, either back or forward chaining, will not be reliant on the RDBMS mapping.
- Cons:
- Requires that the data is effectively duplicated between the RDBMS and triples store.
- The materialized triples will never be 100% concurrent with the RDBMS data.
- Requires the definition of, and sustainment of, the mapping model which can easily run to 100’s of individual mapping terms.
- Any changes to the RDBMS data requires a full rebuild of the materialized triple store.
- It is not uncommon that the RDBMS maps to billions of triples, which even with the performance of tools like RDFizer, can take many hours
- Rebuilding the triple store will require that the operational RDBMS is queried, which might be contrary to the policies in place for ad hoc access to an operational data store that is trying to maintain a performance and availability SLA.
- Pros:
Incremental Materialization
Incremental materialization offers a potential middle route: Instead of materializing the entire RDBMS each time a refresh of the triples in the triple store is required, only the changes in the RDBMS are materialized as inserts or deletes of triples. This incremental materialization can occur immediately any DML is committed in the RDBMS, ensuring concurrency between RDBMS and triplestore.
- Pros:
- Performance will not be inhibited by the need to infer the SQL from the SPARQL query.
- Invariably the triple store will fully support SPARQL1.1, such as property path queries.
- Inferencing performance, either back or forward chaining, will not be reliant on the RDBMS mapping.
- Performance of the triplestore will not be interrupted significantly by any incremental change.
- The incrementally materialized triplestore will be close if not 100% concurrent with the RDBMS data.
- A full rebuild of the RDBMS data, which could easily be billions of triples, is not required.
- Since only changes in the RDBMS need to be queried, incremental materialization is less likely to impact the RDBMS SLA with regard to performance.
- Cons:
- Requires that the data is effectively duplicated between the RDBMS and triples store.
- Requires the definition of, and sustainment of, the mapping model which can easily run to 100’s of individual mapping terms.
Contact inova8 if you would like to try SQL2RDF.