
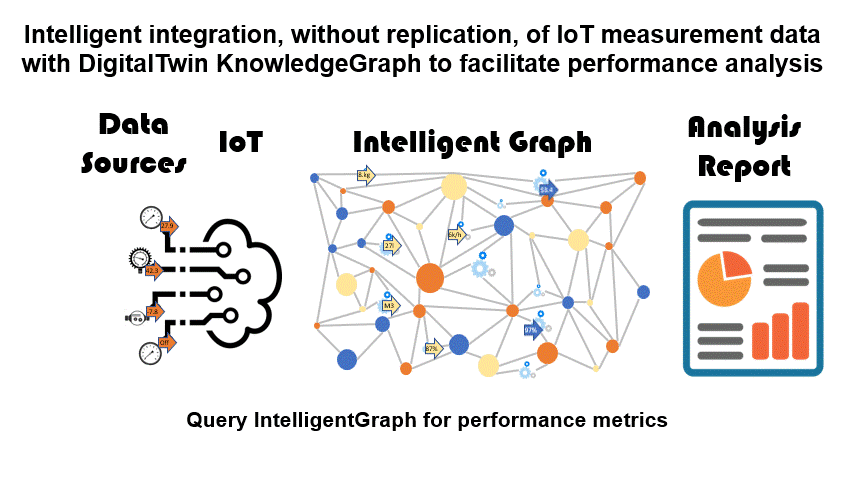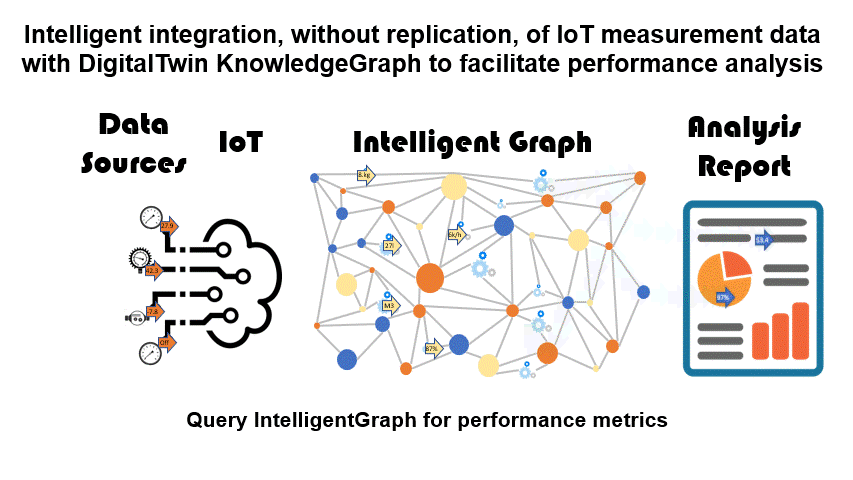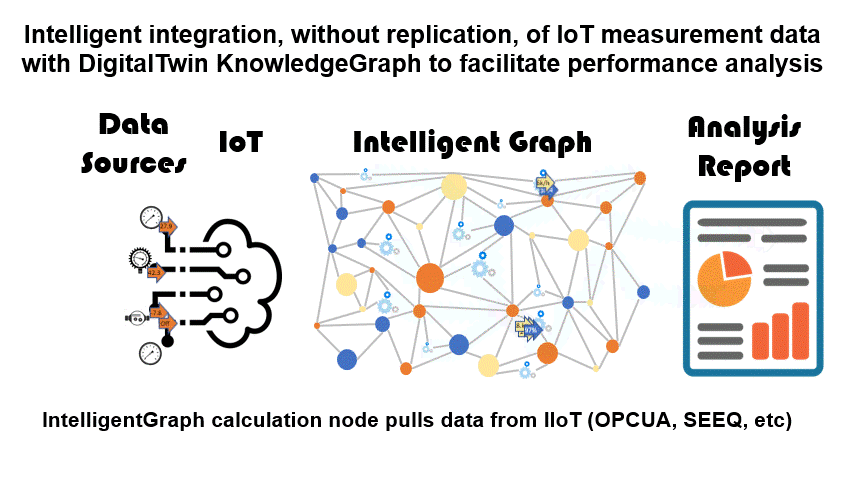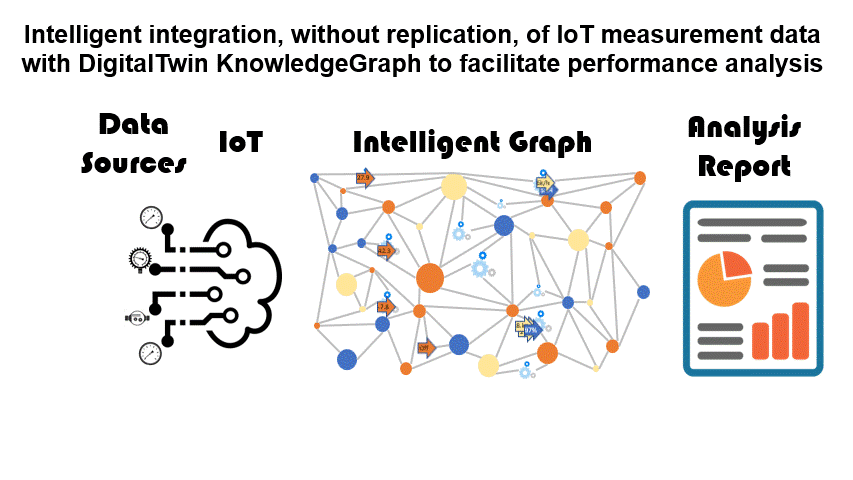
The creation of a DigitalTwin knowledge graph data model confronts the need for access to measurement data in order that the DigitalTwin can create timely performance metrics, identify promptly performance issues, and so on.
However, the quantity of raw data in an Industrial IoT is staggering. A typical process manufacturing plant might have greater than 100,000 measurement points each of which is streaming data by the second or even faster. So how can the raw data be integrated to allow performance analysis?
Just … important😓:
- Someone(?) determines a subset of the data that can and should be replicated.
- A problem is that it is inevitable someone will ask a yet unformulated question about data that has *not* been replicated. Can you afford to keep revising your ETL?
Just … in case😧:
- The bullet is bitten and all data is replicated.
- An issue is the DigitalTwin now has to resolve the problem of handling vast quantities of data that has already been solved by IIoT applications. Why not stick to solving unsolved problems?
Just … reporting😫:
- Someone writes a dedicated application that pulls data from the DigitalTwin and the IIoT just when reporting.
- A problem is that every new performance metric or calculation requires another dedicated application, even if that same metric has been already created in another application.
Just … in time😂:
- The KnowledgeGraph pulls the IIoT data whenever required by an IntelligentGraph calculation.
- There are no limits on what IIoT data can be requested, but no storage or replication issues either. Also, the IntelligentGraph calculations can access the results of other IntelligentGraph calculations, simplifying the deployment of metrics.
See this short video demonstration of how easy an #IoT-connected #DigitalTwin of a process plant #IntelligentGraph can be created: