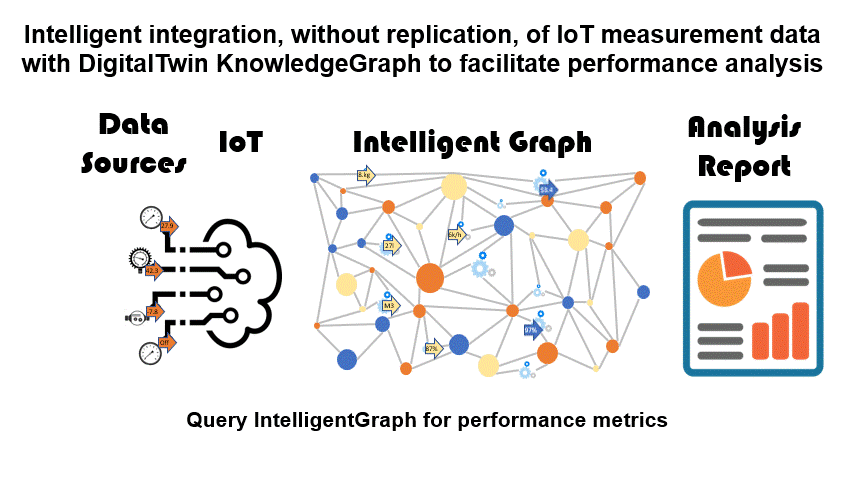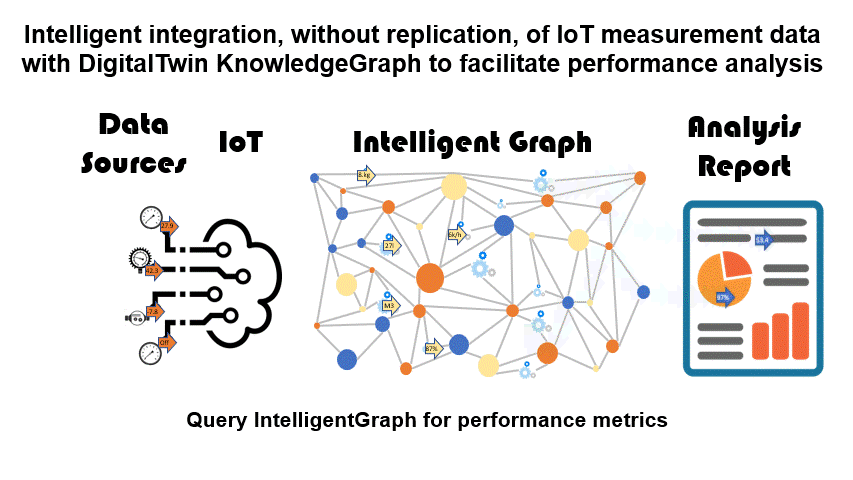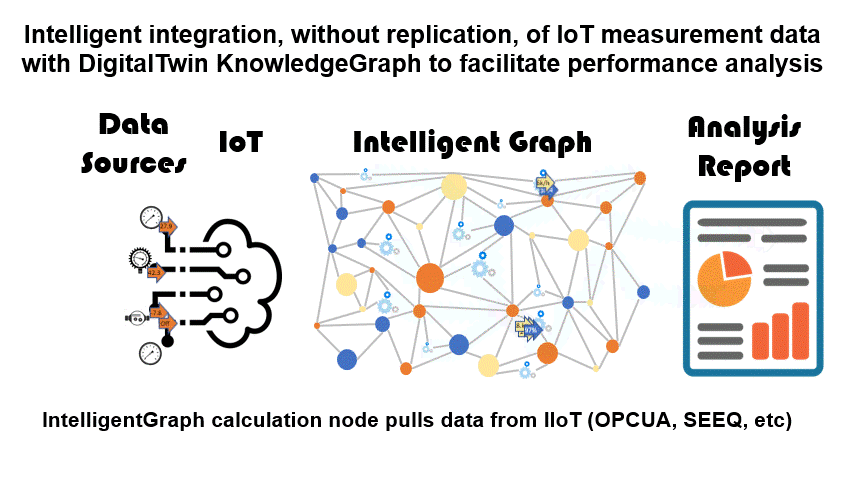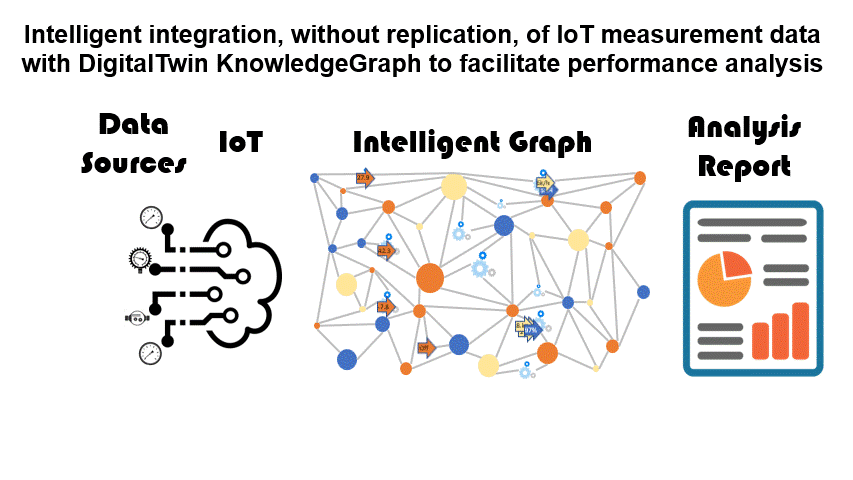
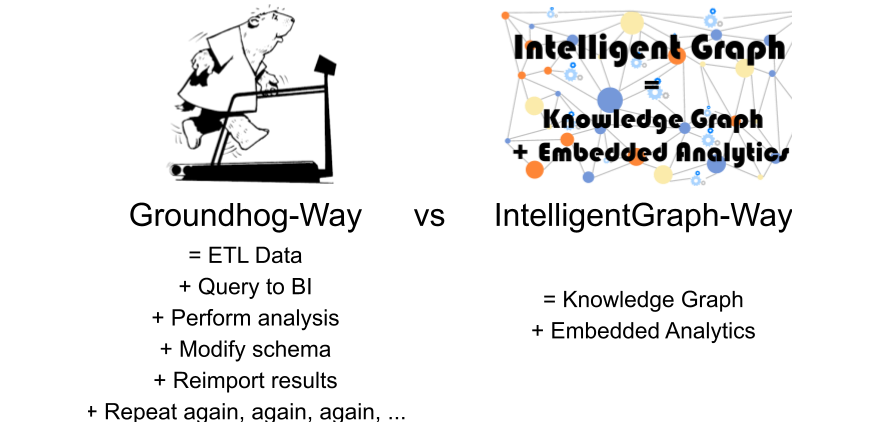
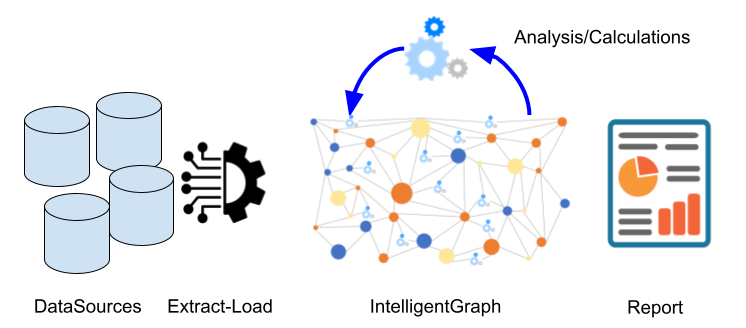
PathQL simplifies finding paths through the maze of facts within a KnowledgeGraph. Used within IntelligentGraph scripts it allows data analysis to be embedded within the graph, rather than requiring graph data to be exported to an analysis engine. Used with IntelligentGraph Jupyter Notebooks it provides powerful data analytics
I would suggest that Google does not have its own intelligence. If I search for, say, ‘Arnold Schwarzenegger and Harvard’, Google will only suggest documents that contain BOTH Arnold Schwarzenegger and Harvard. I might be lucky that someone has digested these facts and produced a single web page with the knowledge I want. I might, however, just as easily find a page of fake knowledge relating Arnold to Harvard.
It is undoubtedly true that Google can provide individual facts such as:
- Arnold married to Shriver
- Shriver daughter Joseph
- Joseph alma mater Harvard
However, intelligence is the ability to connect individual facts into a knowledge path.
- KnowledgeGraph models can provide the facts to answer these questions.
- PathQL provides an easy way to discover knowledge by describing paths and connections through these facts.
- IntelligentGraph embeds that intelligence into any KnowledgeGraph as scripts.
 IntelligentGraph-PathQL and Scripting.pdf
IntelligentGraph-PathQL and Scripting.pdf
Genealogical Example
Genealogy is a grandfather of graphs, it is, therefore, natural to organize family trees as a knowledge graph. A typical PathQL question to ask would then be: who are the parents of a male ancestor, born in Maidstone, of this individual, and what is that relationship?
Industrial Internet of Things (IIoT) Example
The Industrial Internet of Things (IIot) is best modeled as an interconnected graph of ‘thing’ nodes. These things might be sensors producing measurements, the equipment to which the sensors are attached, or how the equipment is interconnected to form a functioning plant. However, the ‘intelligence’ about why the plant is interconnected is what an experienced (aka intelligent, knowledgeable) process engineer offers. To support such intelligence with a knowledge graph requires answering PathQL questions such as
- If the V101 bottoms pump stops how does this affect the product flow from this production unit?
- If the FI101 instrument fails how does this affect the boiler feed temperature?
- What upstream could possibly be affecting this stream’s quality?
- … and so on.
Why PathQL?
SPARQL is a superb graph pattern query language, so why create another?
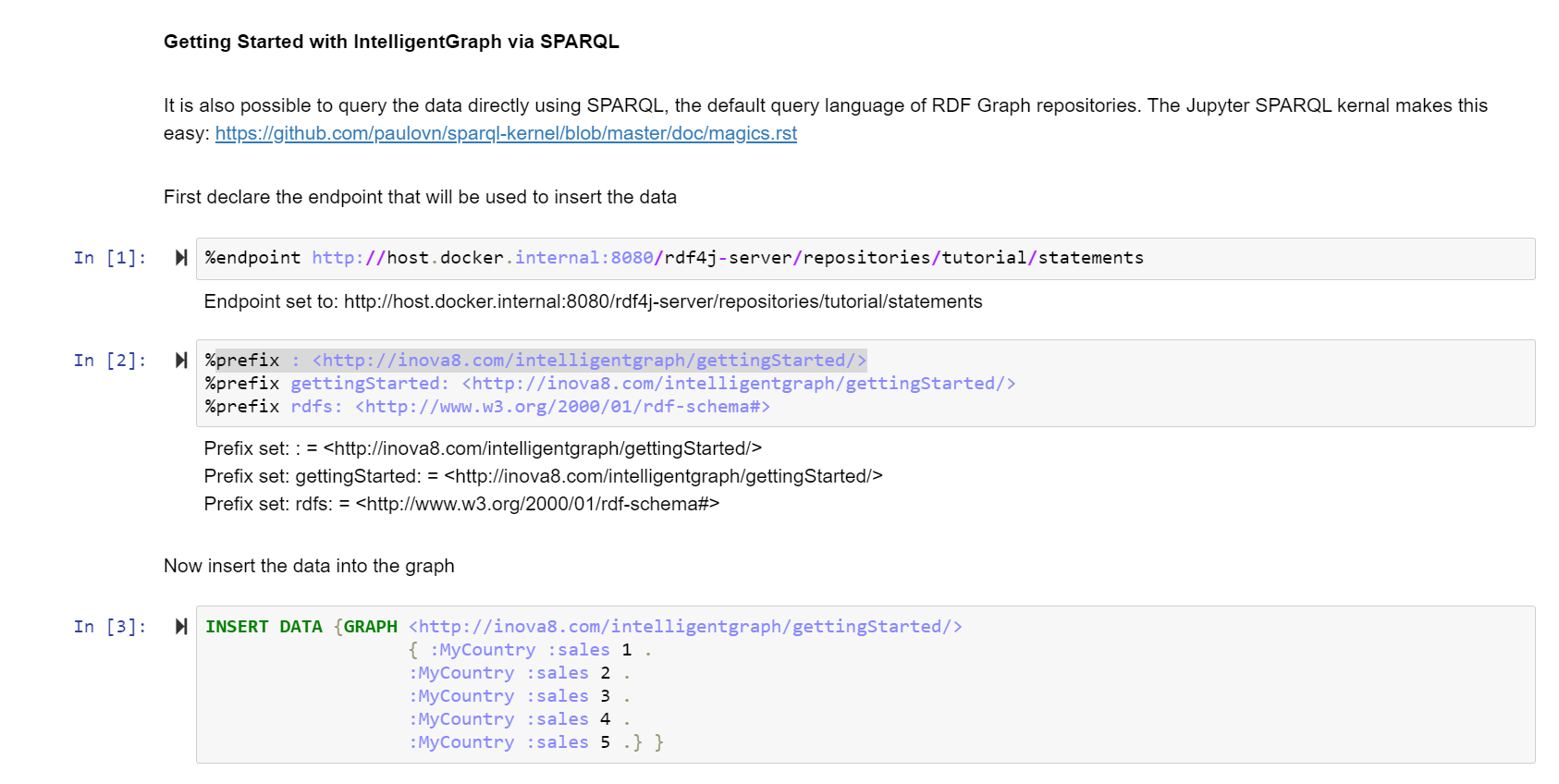
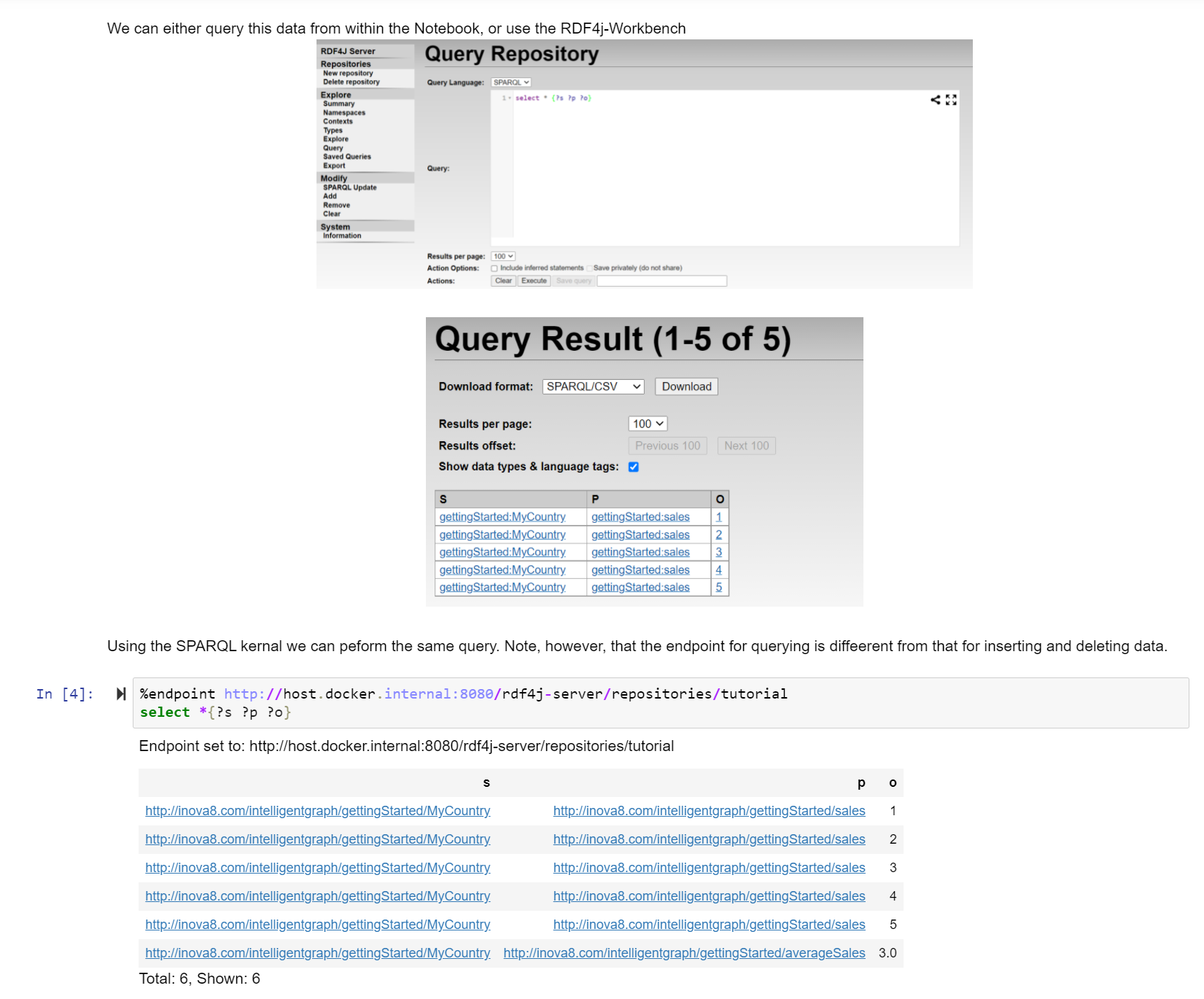
PathQL started out as the need to traverse the nodes and edges in a triplestore both without the benefit of SPARQL and within a scripting language of IntelligentGraph. IntelligentGraph works by embedding the calculations within the graph. Therefore, just like a spreadsheet calculation can access other ‘cells’ within its spreadsheet, IntelligentGraph needed a way of traversing the graph through interconnected nodes and edges to other nodes from where relevant values can be retrieved.
I didn’t want to create a new language, but it was essential that the IntelligentGraphprovided a very easy way to navigate a path through a graph. It then became clear that, as powerful as SPARQL is for graph pattern matching, it can be verbose for matching path patterns. PathQL was born, but not without positive prodding from my colleague Phil Ashworth.
Adding Intelligence to Graphs with Scripts
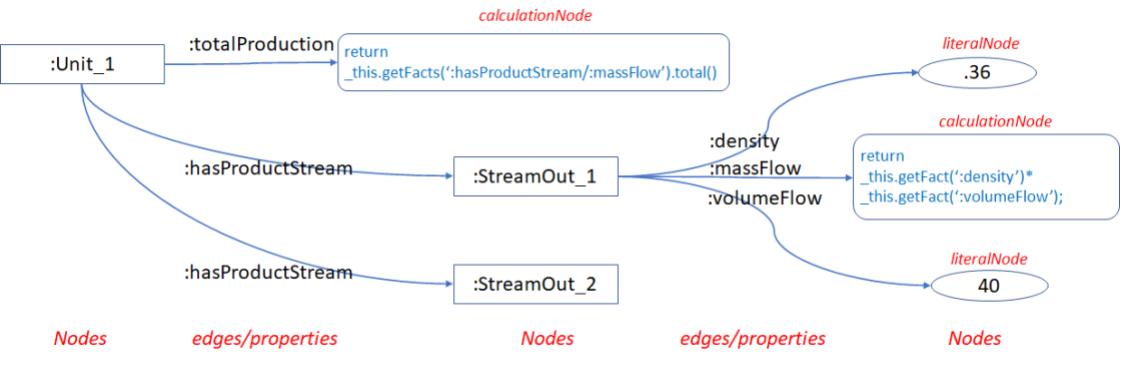
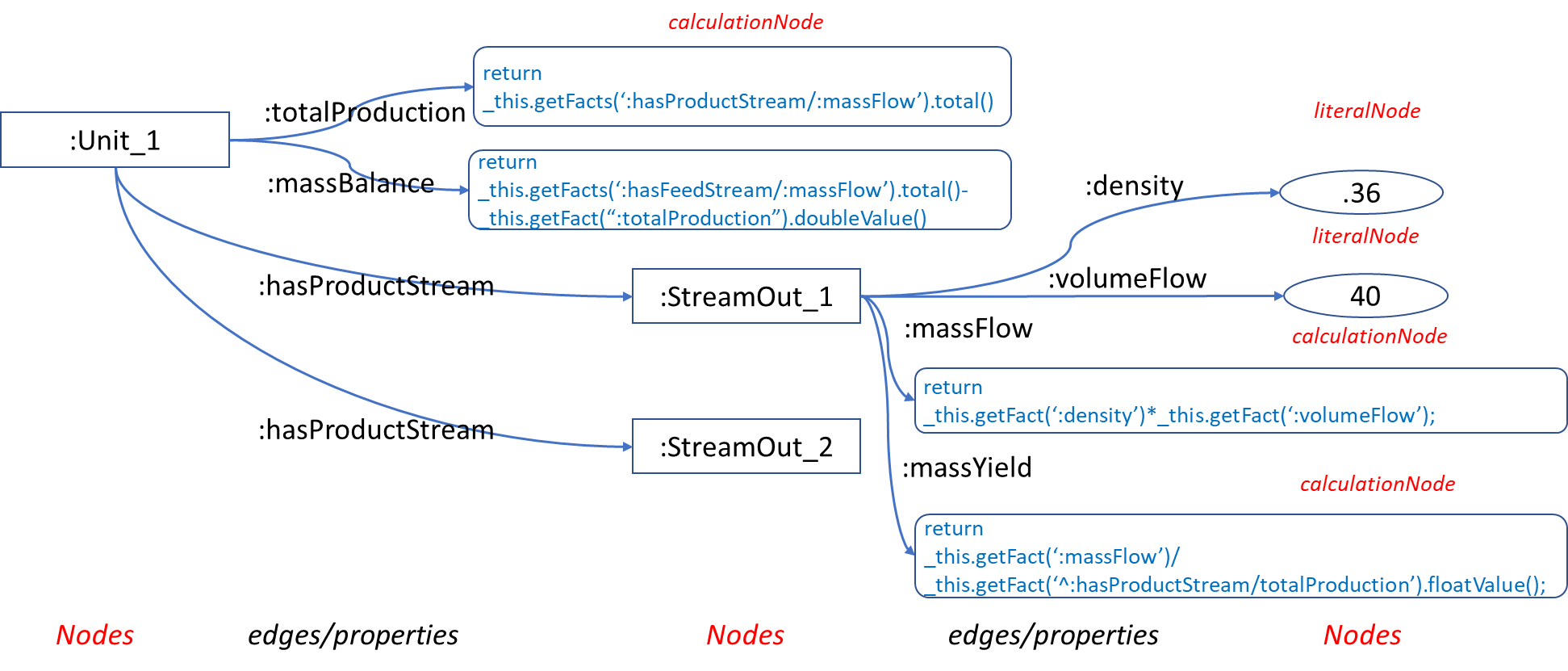
Typically, a graph node will have associated attributes with values, such as a stream with volumeFlow and density values. These values might have been imported from some external system or other:
Stream Attributes:
:Stream_1
:density ".36"^^xsd:float ;
:volumeFlow "40"^^xsd:float .
:Stream_2 ....
The ‘model’ of the streams can be captured as edges associated with the Unit:
:Unit_1
:hasProductStream :Stream_1 ;
:hasProductStream :Stream_2 .
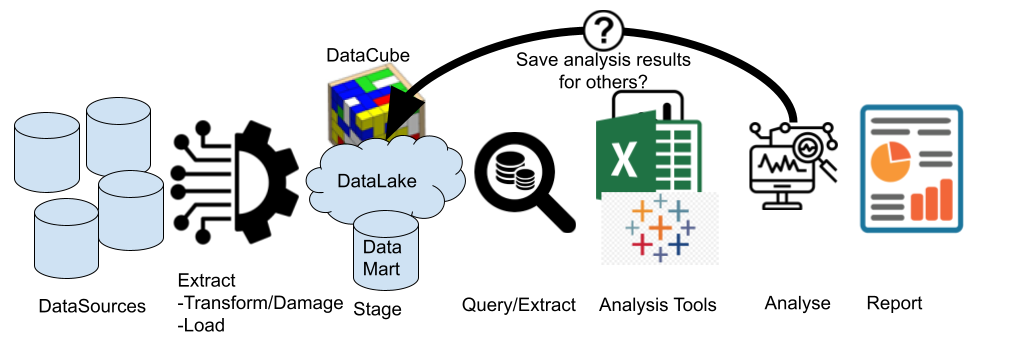
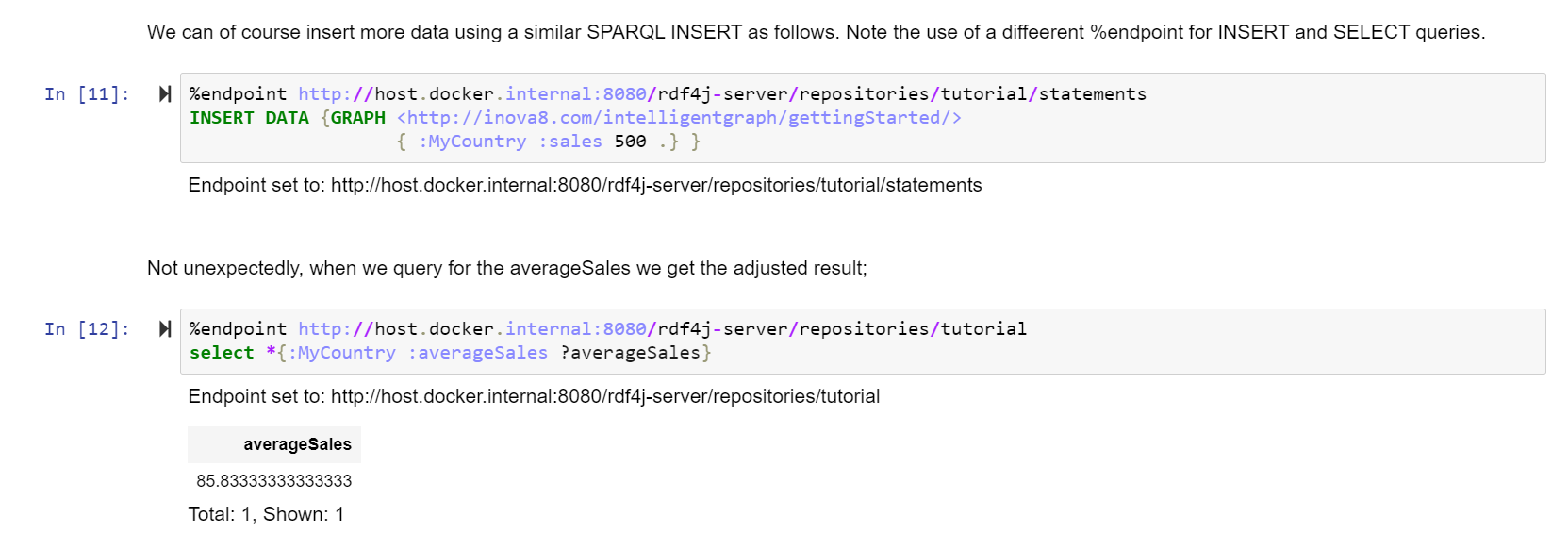
However, most ‘attributes’ that we want to see about a thing are not measured directly. Instead, they need to be calculated from other values. This is why we end up with spreadsheet-hell: importing the raw data from the data sources into a spreadsheet simply so we can add calculated columns, the values of which are rarely exported back to the source-databases.
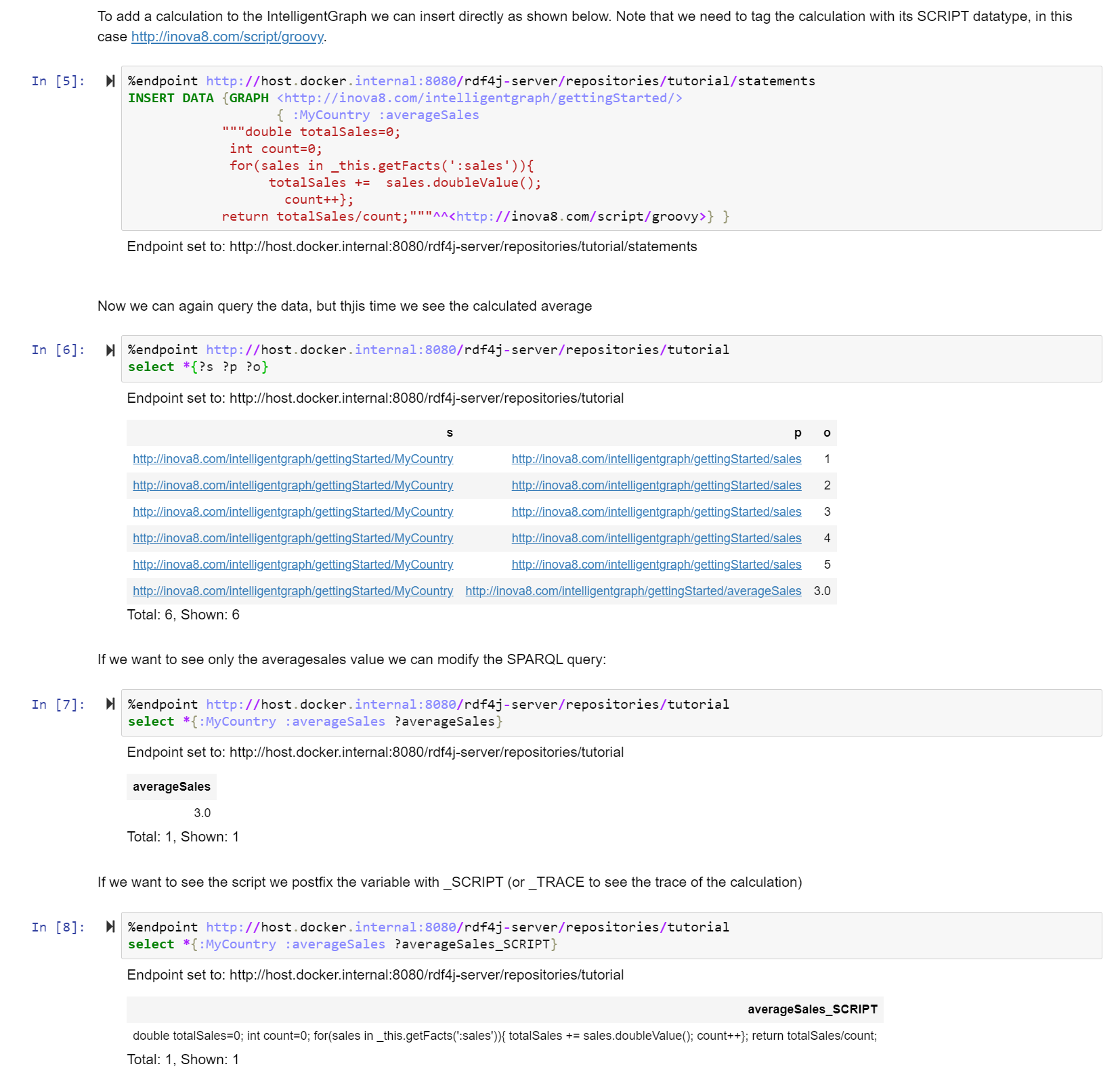
IntelligentGraph allows these calculations to be embedded in the graph as literals[1] with a datatype whose local name corresponds to one of the installed script languages:
:Stream_1
:massFlow
"_this.getFact(‘:density’)*
_this.getFact(‘:volumeFlow’);"^^:groovy .
:Unit_1
:totalProduction
"var totalProduction =0.0;
for(Resource stream : _this.getFacts(‘:hasProductStream’))
{
totalProduction += stream.getFact(‘:massFlow’);
}
return totalProduction; "^^:groovy .
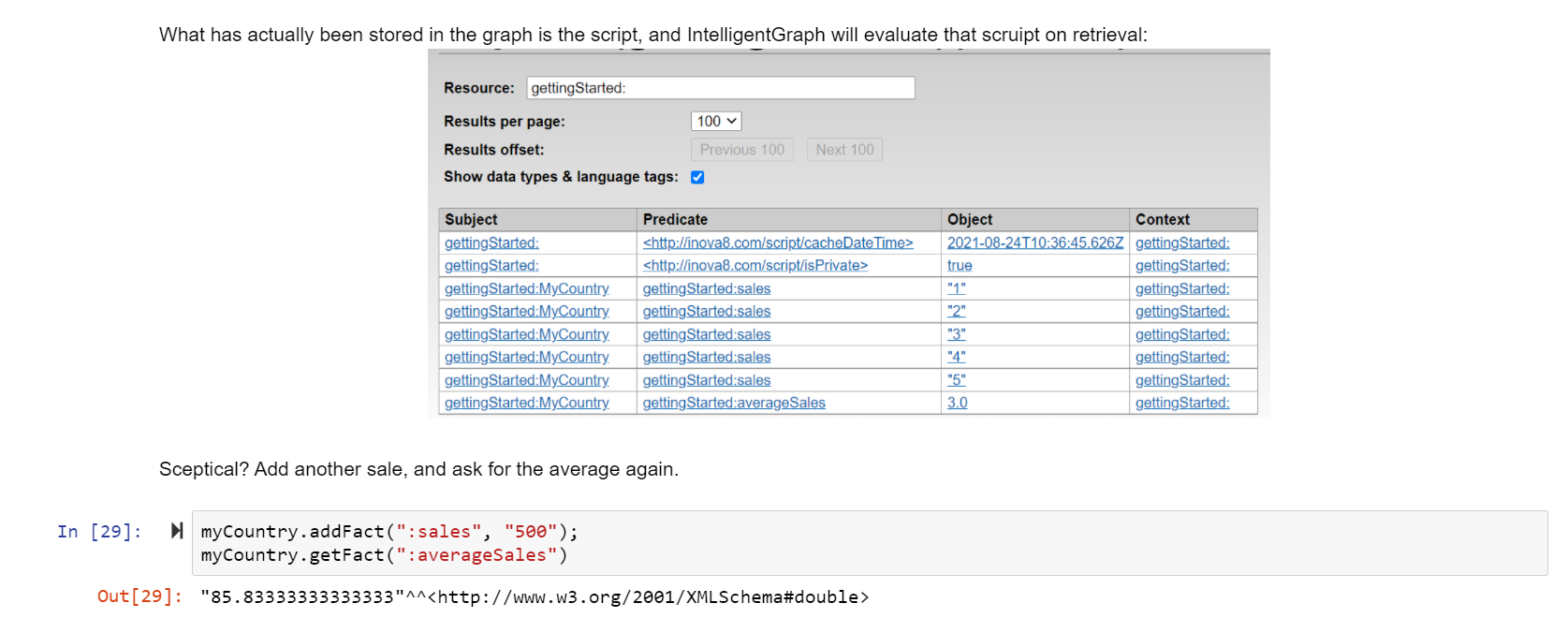
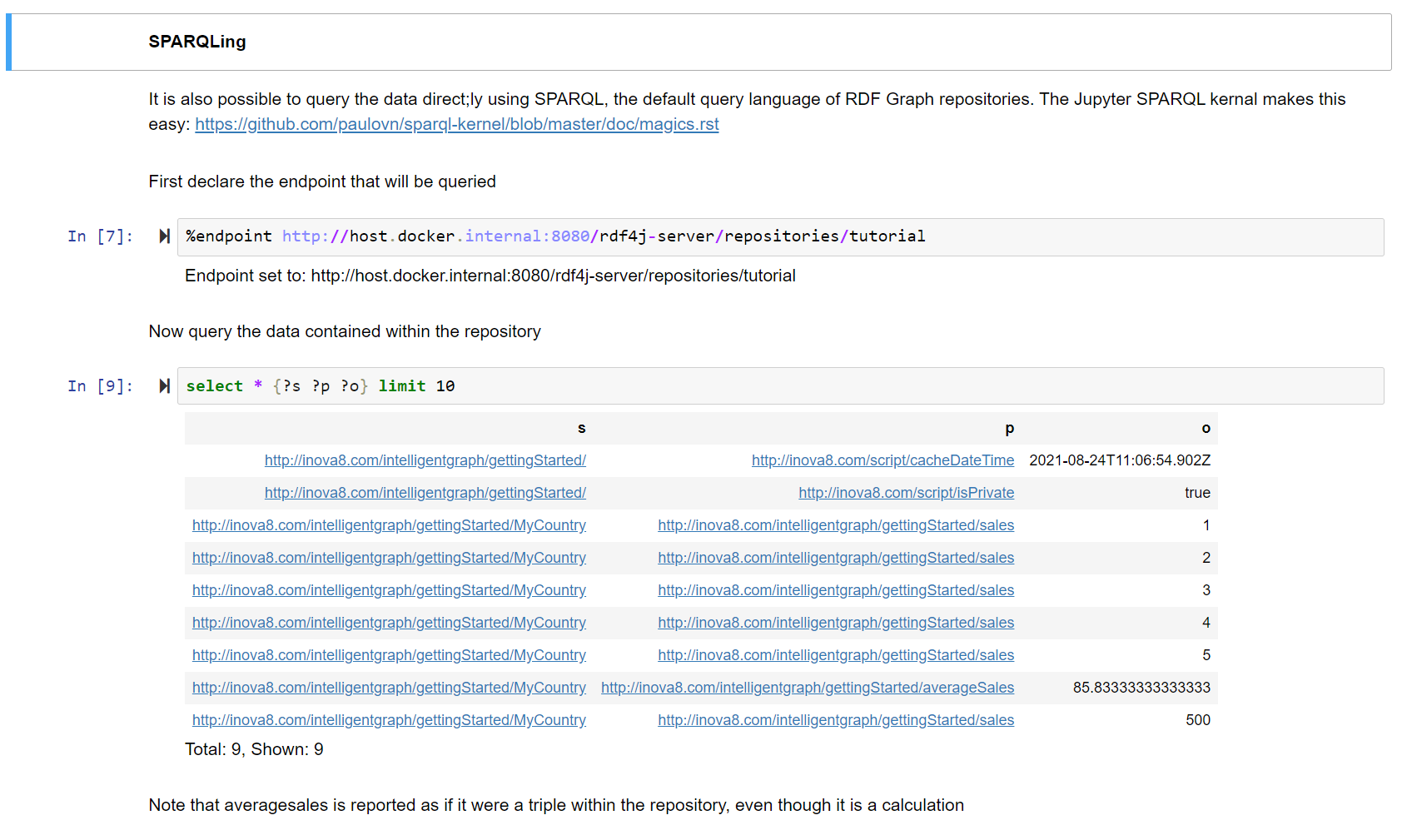
Instead of returning the object literal value (aka the script), the IntelligentGraph will return the result value for the script.
We can write this script even more succinctly using the expressive power of PathQL:
:Unit_1 :totalProduction "return _this.getFacts(‘:hasProductStream/:massFlow’).total(); "^^:groovy .
PathQL
Spreadsheets are not limited to accessing just adjacent cells; neither is the IntelligentGraph. PathQL provides a powerful way of navigating from one Thing node to others. PathQL was inspired by SPARQL and propertyPaths, but a richer, more expressive, path searching was required for the IntelligentGraph.
Examples

Genealogy Example Graph
Examples of PathQL that explore this genealogy are as follows:
-
_this.getFact(“:parent”)
- will return the first parent of _this.
PathQL Formal Syntax
The parts of a PathPattern are defined below. The formal syntax in BNF is here: PathPattern Formal Syntax
IRIRef:
The simplest pathPattern is an IRI of the predicate, property, or edge:
:parent
An unprefixed qname using the default namespace.
ft:parent
A prefixed qname using the namespace model.
<http://inova8.com/ft/hasParent>
A full IRI.
PathAlternative:
A pathPattern can consist of a set of alternative edges:
:parent|:hasChild
Alternative edges to ‘close relatives’ of the :subjectThing.
PathSequence:
A pathPattern can consist of a sequence of edges:
:parent/:hasChild
sequence of edges to the set of siblings of the start thing.
Inverse Modifier:
A modifier prefix to a predicate indicating that it should be navigated in the reverse direction (objectàsubject) instead of subjectàobject:
:parent/^:parent
A sequence of edges to the set of siblings of the start thing since ^:parent is equivalent to :hasChild.
Reified Modifier:
A modifier prefix to a predicate indicating that it should be assumed that the subject-predicate-object is reified.
@:marriedTo
navigates from the :subjectThing to the :objectThing when the edge has been reified as:
[] rdf:subject :subjectThing ;
rdf:predicate :marriedTo ;
rdf:object :objectThing .
Inverse modifier can also be applied to navigate from the :objectThing to :subjectThing:
^@:marriedTo
navigates from the :objectThing to the :subjectThing
Extended Reification Modifier:
The reification type and the predicate of an extended reification:
:Marriage@:civilPartnership
navigates from the :subjectThing to the :objectThing when the edge has been reified as a class that is a :Marriage, which is rdfs:subClassOf rdf:Statement with a predicate of :civilPartnership. For example:
[] a :Marriage
:partner1 :subjectThing ;
:marriageType :civilPartnership ;
:partner2 :objectThing .
:Marraige rdfs:subClassOf rdf:Statement .
:partner1 rdf:subPropertyOf rdf:subject .
:marriageType rdf:subPropertyOf rdf:predicate.
:partner2 rdf:subPropertyOf rdf:object .
An inverse modifier can also be applied to navigate from the :objectThing to :subjectThing
^:Marriage@:marriedTo
navigates from the :objectThing to the :subjectThing in the extended reification.
Dereification Modifier:
Instead of navigating to the objectThing of a reification, the dereification operator navigates to the reification thing:
@:marriedTo#
navigates from the :subjectThing to the :marriage object.
@:marriedTo#/:at
navigates from the :subjectThing to the location :at which the marriage took place
@:marriedTo#/:when
navigates from the :subjectThing to the date :when the marriage took place
Path Filter:
A path filter can be applied to any point in a pathPattern to limit the subsequent paths. A path filter is like a SPARQL PropertyListNotEmpty graph pattern. However, it includes comparison operators lt, gt etc
:parent[:gender :male]
Navigates to the male parent.
:parent[:gender :male]/:parent[:gender :female]
Navigates to the paternal grandmother.
:volumeFlow[gt “50”]
Navigates only if the value is greater than “50”.
:appearsOn[eq :calc2graph1]
Navigates only if the objectNode value is :calc2graph1.
:appearsOn[ rdfs:label "Calc2Graph1"]
Navigates only if the objectNode has a rdfs:label with value “Calc2Graph1”.
:appearsOn[eq [ rdfs:label "Calc2Graph1"]]
Navigates only if the objectNode value is a node whose label is “Calc2Graph1”.
Cardinality:
Repeats the pathPattern between the range of minimum and maximum cardinality
:parent{1,5}
Finds the 1 to 5th ancestor of the reference node.
:parent[:gender :male]{1,5}
Finds the 1 to 5th male ancestor via the male line of the reference node.
Further Example Scripts
The following illustrates the IntelligentGraph scripts to perform the plant analysis example
Return Scalar Value
return 40;
Get Related Property Value
return _this.getFact(":testProperty2").doubleValue()
Calculate Stream Mass Flow
var result= _this.getFact(":volumeFlow").floatValue()* _this.getFact(":density").floatValue();
return result;
Calculate Unit Mass Throughput
return _this.getFacts(":hasProductStream/:massFlow").total();
Calculate Stream Mass Yield
var result= _this.getFact(":massFlow").floatValue()/ _this.getFact("^:hasStream/:massThroughput").floatValue();
return result;
Calculate Unit Mass Balance
return _this.getFacts(":hasFeedStream/:massFlow").total()
- _this.getFacts(":hasProductStream/:massFlow").total();
Path Navigation Functions
The spreadsheets’ secret sauce is the ability of a cell formula to access values of other cells, either individually or as a set. The IntelligentGraph provides this functionality with several methods associated with Thing, which are applicable to the _this Thing initiated for each script with the subject Thing.
Thing.getFact(String pathQL) returns Resource
Returns the value of the node referenced by the pathQL, for example “:volumeFlow” returns the object value of the :volumeFlow edge relative to _this node. The pathPattern allows for more complex path navigation.
Thing.getFacts(String pathQL) returns ResourceResults
Returns the values of nodes referenced by the pathQL, for example “:hasProductStream” returns an iterator for all object values of the :hasProductStream edge relative to _this node. The pathPattern allows for more complex path navigation.
Thing.getPath(String pathQL) returns Path
Returns the first (shortest) path referenced by the pathQL, for example “:parent{1..5}” returns the path to the first ancestor of _this node. The pathQL allows for more complex path navigation.
Thing.getPaths(String pathQL) returns PathResults
Returns all paths referenced by the pathQL, for example “:parent{1..5}” returns an iterator, starting with the shortest path, for all paths to the ancestors of _this node. The pathQL allows for more complex path navigation.
Graph.getThing(String subjectIRI) returns Thing
Returns a node as defined by the IRI
Script Context Variables
Each script has access to the following predefined variables that allow the script to access the context within which it is being run.
_this, a Thing corresponding to the subject of the triples for which the script is the object. Since this is available, helper functions are provided to navigate edges to or from this ‘thing’ below:
_property, a Thing corresponding to the predicate or property of the triples for which the script is the object.
_customQueryOptions, a HashMap<String, Value> of name/value pairs corresponding to the pairs of additional arguments to the SPARQL extension function. These are useful for passing application-specific parameters.
_builder, a RDF4J graph builder object allowing a graph to be constructed (and manipulated) within the script. A graph cannot be returned from a SPARQL function. However the IRI of the graph can be returned, and any graph created by a script will be persisted.
_tripleSource, the RDF4J TripleSource to which the subject, predicate, triple belongs.
PathQL BNF
The formal syntax of the PathPattern is defined as follows using ANTLR4 BNF:
grammar PathPattern;
// PARSER RULES
queryString : pathPattern queryOptions? EOF ;
queryOptions : ( queryOption )+;
queryOption : KEY '=' literal ('^^' type )?;
type : qname;
pathPattern : binding ('/'|'>') pathPatterns #boundPattern
| binding #matchOnlyPattern
| pathPatterns #pathOnlyPattern;
binding : factFilterPattern ;
pathPatterns : pathEltOrInverse cardinality? #Path
| pathPatterns '|' pathPatterns #PathAlternative
| pathPatterns ('/'|'>') pathPatterns #PathSequence
| negation? '(' pathPatterns ')' cardinality? #PathParentheses;
cardinality : '{' INTEGER (',' ( INTEGER )? )? '}' ;
negation : '!';
pathEltOrInverse: negation? INVERSE? predicate ;
predicate : ( reifiedPredicate
| predicateRef
| rdfType
| anyPredicate ) factFilterPattern? ;
anyPredicate : ANYPREDICATE ;
reifiedPredicate: iriRef? REIFIER predicateRef factFilterPattern? dereifier? ;
predicateRef : IRI_REF | rdfType | qname | pname_ns ;
iriRef : IRI_REF | qname | pname_ns ;
dereifier : DEREIFIER ;
factFilterPattern: '[' propertyListNotEmpty ']';
propertyListNotEmpty: verbObjectList ( ';' ( verbObjectList )? )* ;
verbObjectList : verb objectList;
verb : operator | pathEltOrInverse ;
objectList : object ( ',' object )*;
object : iriRef | literal | factFilterPattern | BINDVARIABLE ;
qname : PNAME_NS PN_LOCAL;
pname_ns : PNAME_NS ;
literal : (DQLITERAL | SQLITERAL) ('^^' (IRI_REF | qname) )? ;
operator : OPERATOR ;
rdfType : RDFTYPE ;
// LEXER RULES
KEY : '&' [a-zA-Z]+ ;
INTEGER : DIGIT+ ;
BINDVARIABLE : '%' DIGIT+ ;
fragment
DIGIT : [0-9] ;
INVERSE : '^';
REIFIER : '@';
DEREIFIER : '#';
RDFTYPE : 'a';
ANYPREDICATE : '*' ;
OPERATOR : 'lt'|'gt'|'le'|'ge'|'eq'|'ne'|'like'|'query'|'property';
DQLITERAL : '"' (~('"' | '\\' | '\r' | '\n') | '\\' ('"' | '\\'))* '"';
SQLITERAL : '\'' (~('\'' | '\\' | '\r' | '\n') | '\\' ('\'' | '\\'))* '\'';
IRI_REF : '<' ( ~('<' | '>' | '"' | '{' | '}' | '|' | '^' | '\\' | '`') | (PN_CHARS))* '>' ;
PNAME_NS : PN_PREFIX? (':'|'~') ;
VARNAME : '?' [a-zA-Z]+ ;
fragment
PN_CHARS_U : PN_CHARS_BASE | '_' ;
fragment
PN_CHARS : PN_CHARS_U
| '-'
| DIGIT ;
fragment
PN_PREFIX : PN_CHARS_BASE ((PN_CHARS|'.')* PN_CHARS)? ;
PN_LOCAL : ( PN_CHARS_U | DIGIT ) ((PN_CHARS|'.')* PN_CHARS)? ;
fragment
PN_CHARS_BASE : 'A'..'Z'
| 'a'..'z'
| '\u00C0'..'\u00D6'
| '\u00D8'..'\u00F6'
| '\u00F8'..'\u02FF'
| '\u0370'..'\u037D'
| '\u037F'..'\u1FFF'
| '\u200C'..'\u200D'
| '\u2070'..'\u218F'
| '\u2C00'..'\u2FEF'
| '\u3001'..'\uD7FF'
| '\uF900'..'\uFDCF'
| '\uFDF0'..'\uFFFD' ;
WS : [ \t\r\n]+ -> skip ;
[1] SCRIPT Languages
In this case, the script uses Groovy, but any Java 9 compliant scripting language can be used, such as JavaScript, Python, Ruby, and many more.
By default, JavaScript, Groovy, Python JAR are installed. The complete list of compliant languages is as follows
AWK, BeanShell, ejs, FreeMarker, Groovy, Jaskell, Java, JavaScript, JavaScript (Web Browser), Jelly, JEP, Jexl, jst, JudoScript, JUEL, OGNL, Pnuts, Python, Ruby, Scheme, Sleep, Tcl, Velocity, XPath, XSLT, JavaFX Script, ABCL, AppleScript, Bex script, OCaml Scripting Project, PHP, Python, Smalltalk, CajuScript, MathEclipse

 Confucius said, “Tell me and I forget, show me and I remember, let me try and I learn”. Following this sage’s path to intelligence, try IntelligentGraph and PathQL by installing the IntelligentGraph docker image available here.
Confucius said, “Tell me and I forget, show me and I remember, let me try and I learn”. Following this sage’s path to intelligence, try IntelligentGraph and PathQL by installing the IntelligentGraph docker image available here.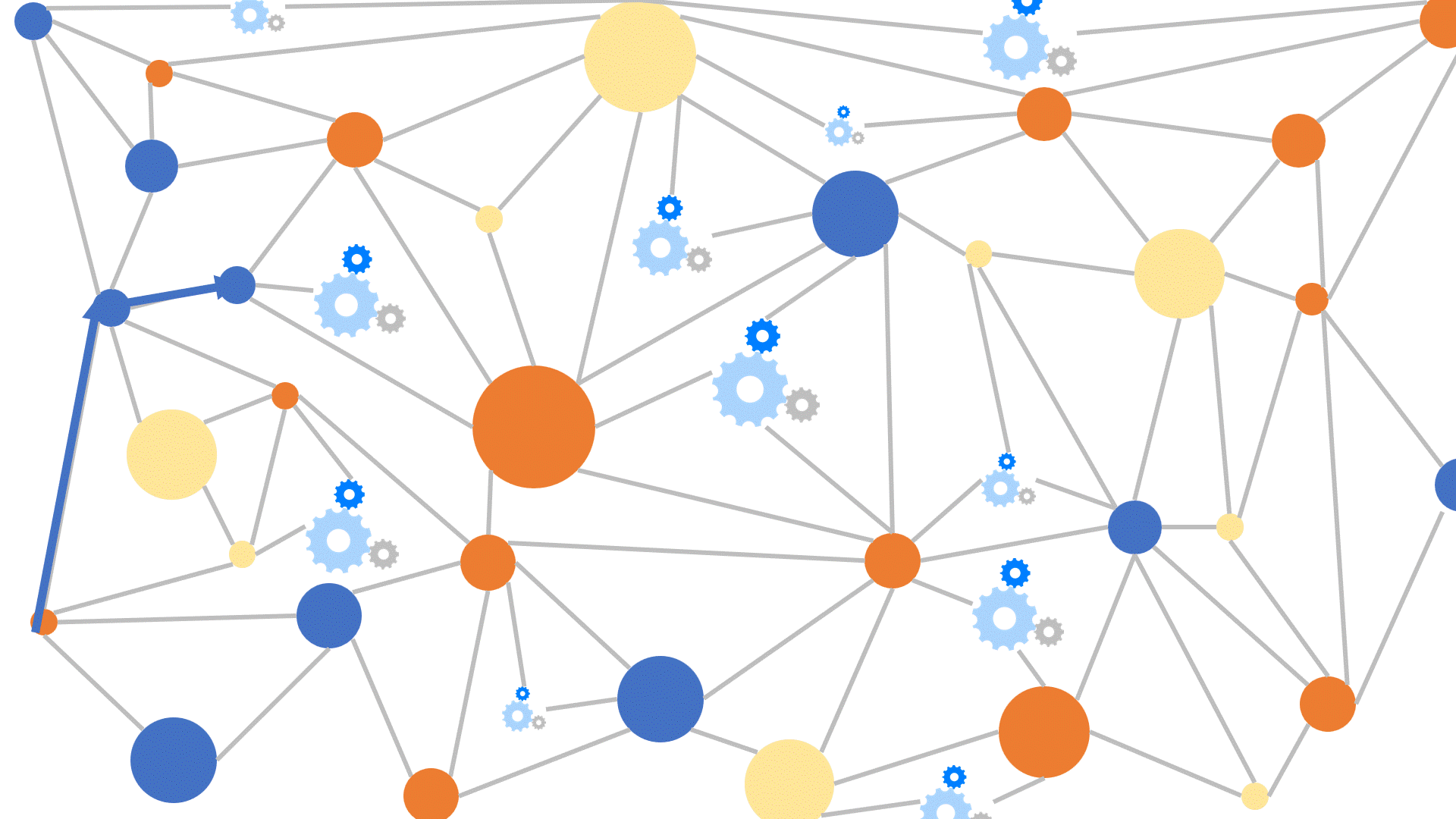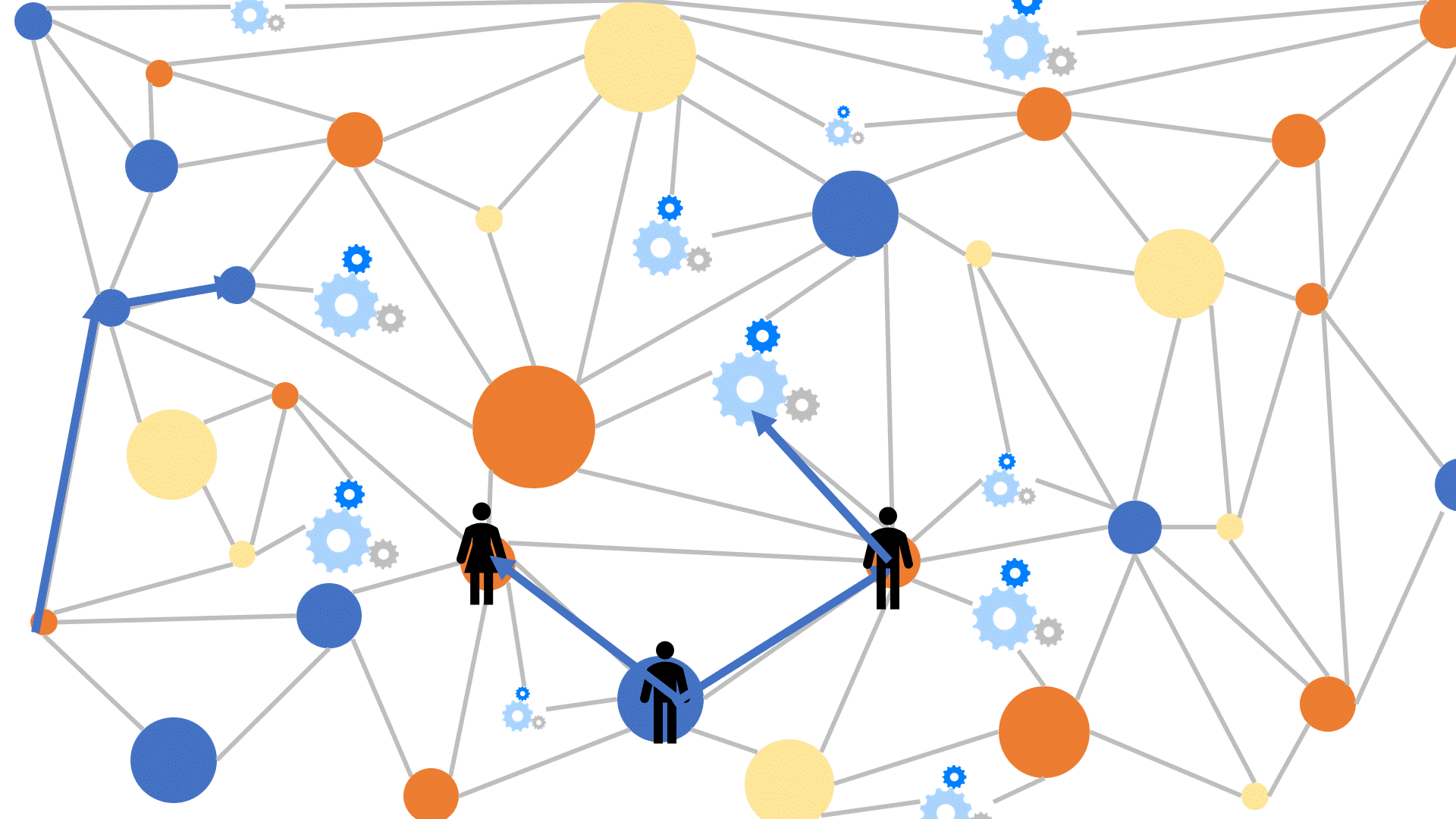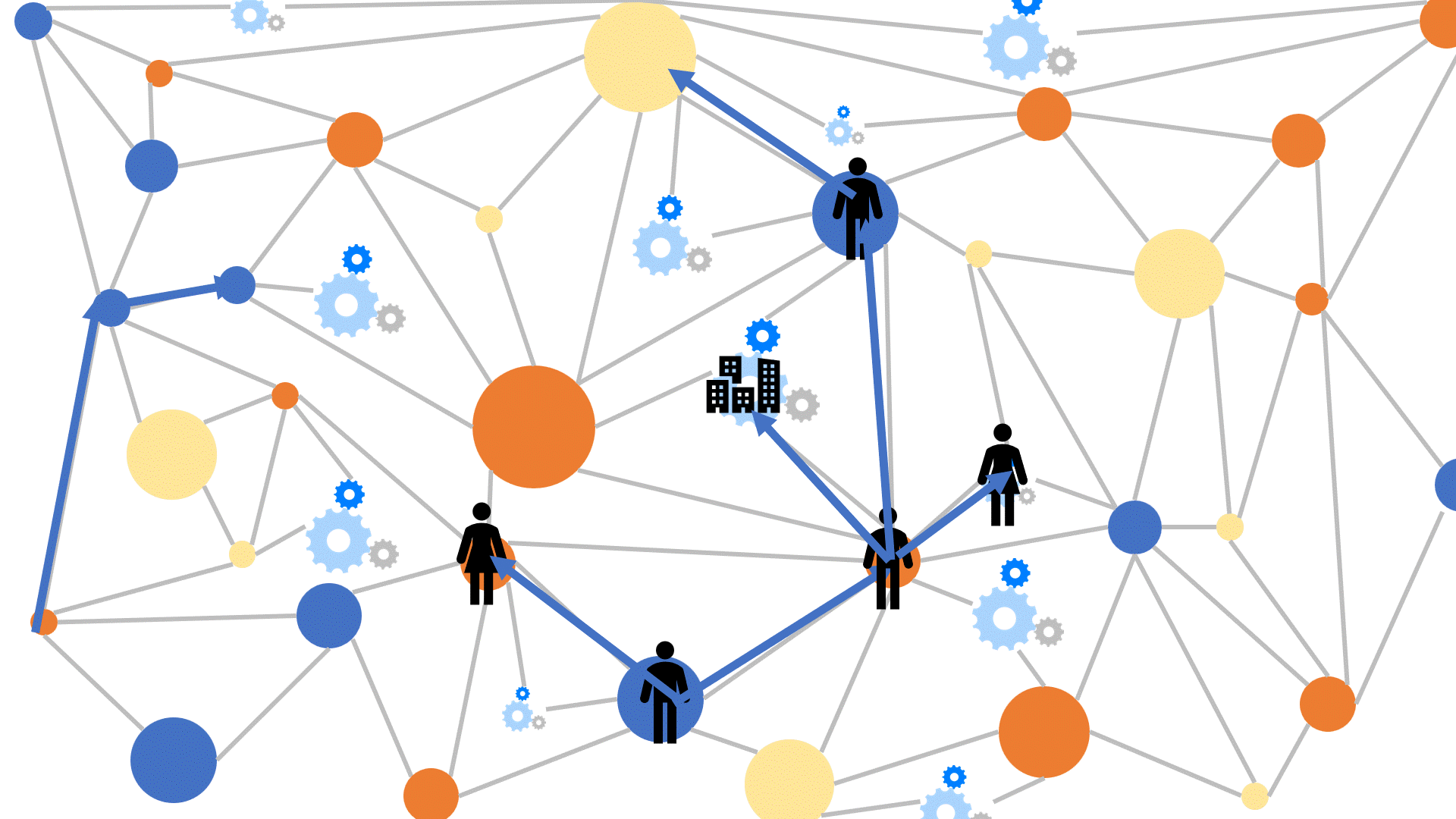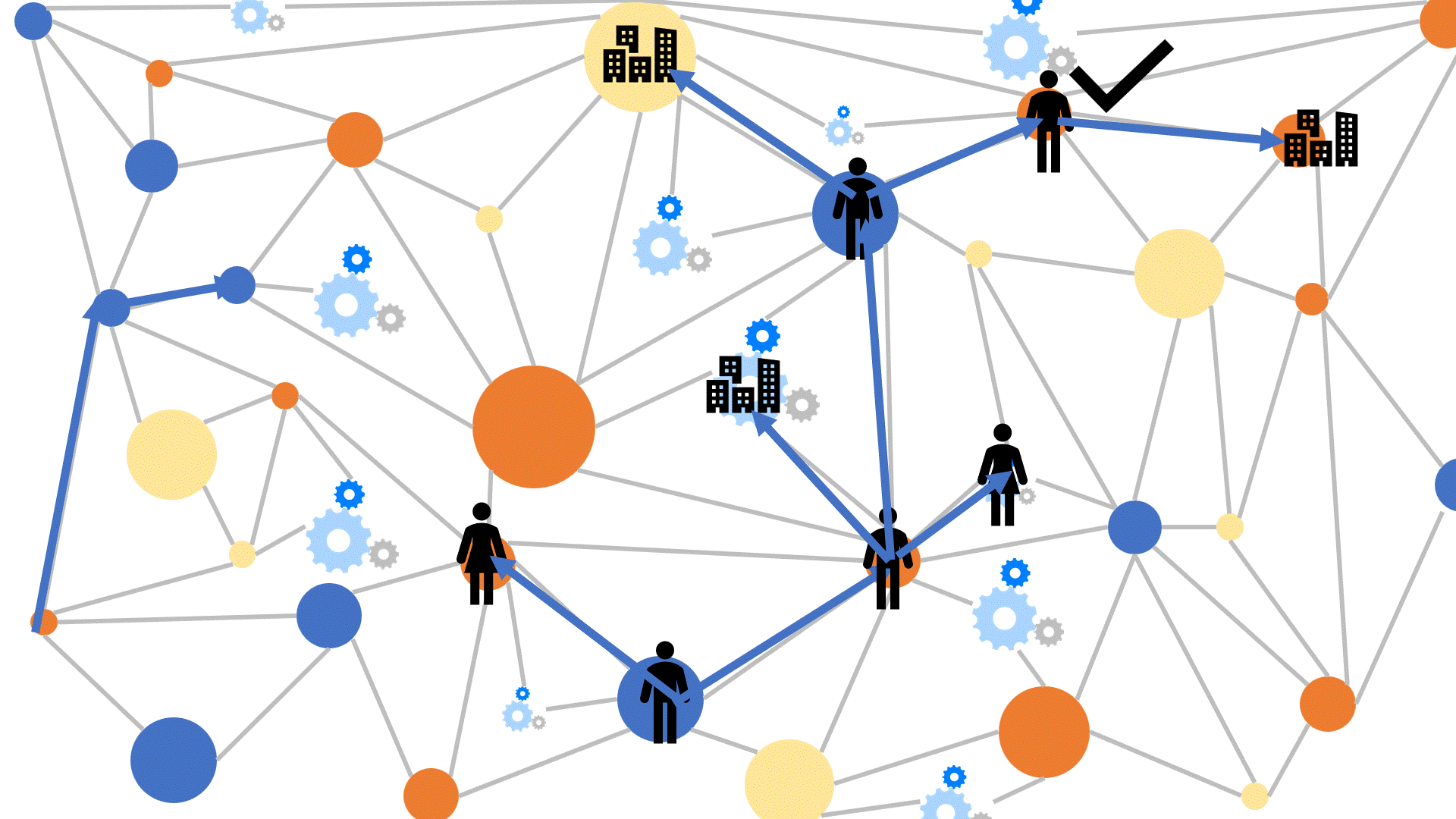

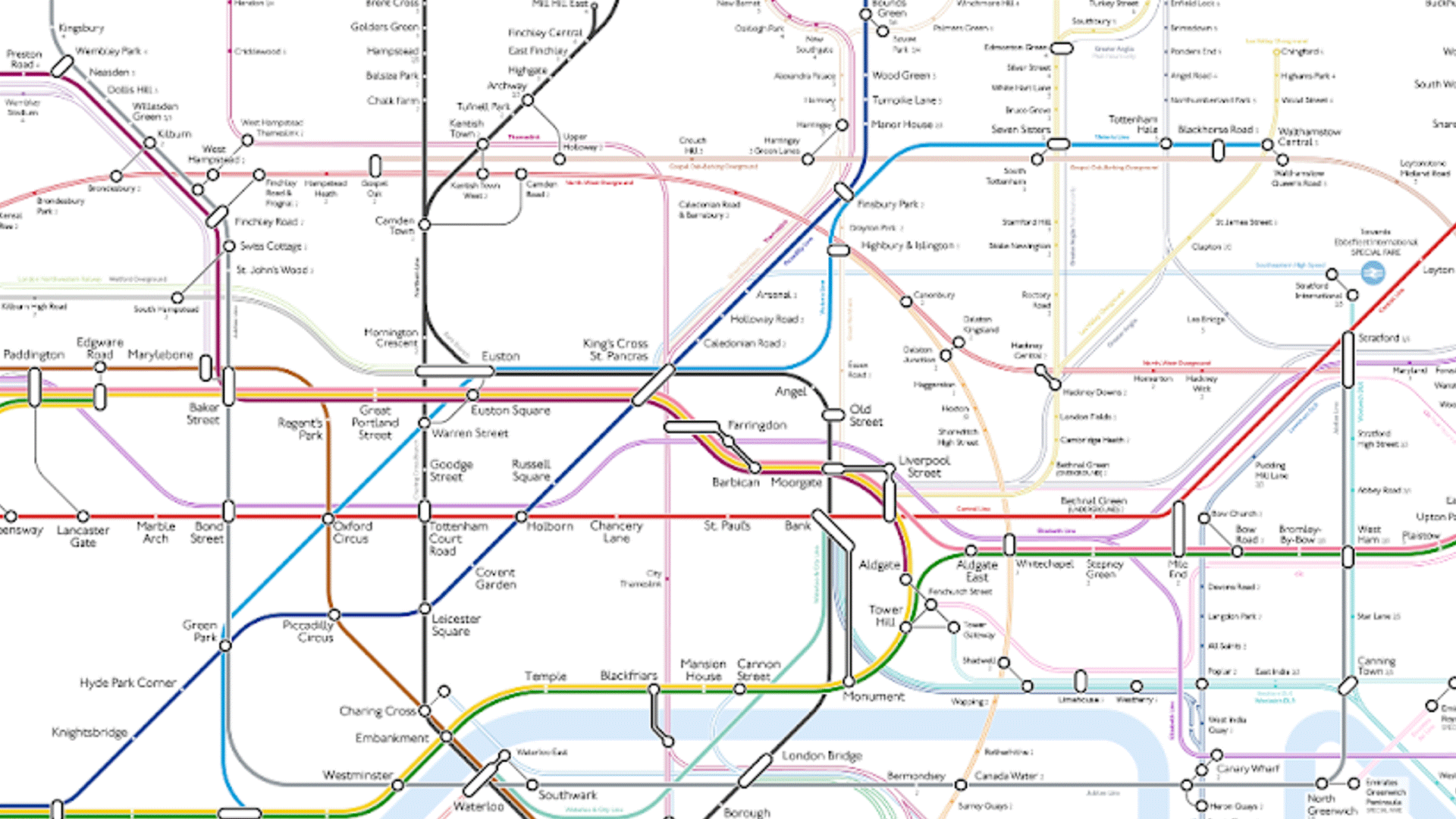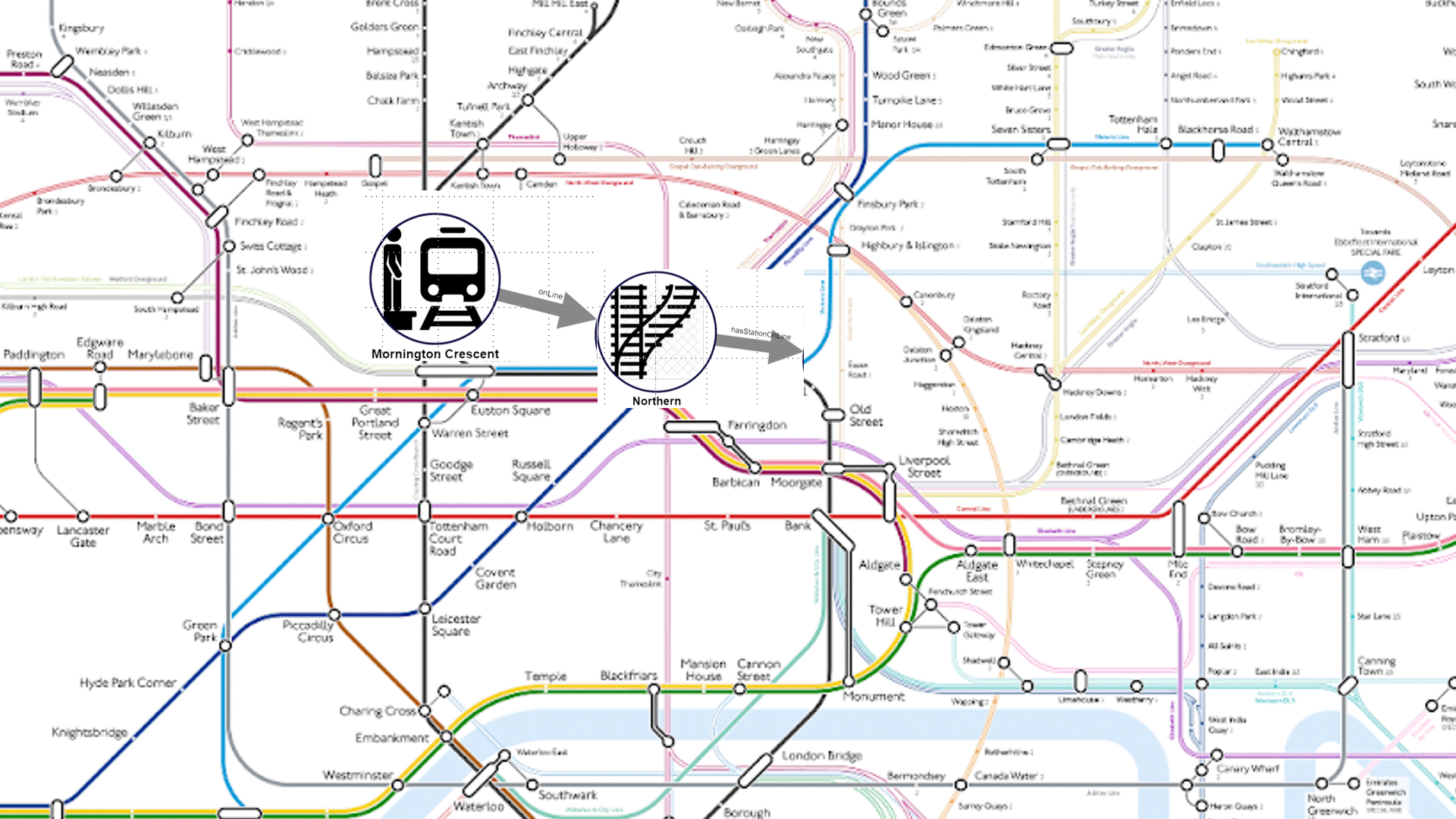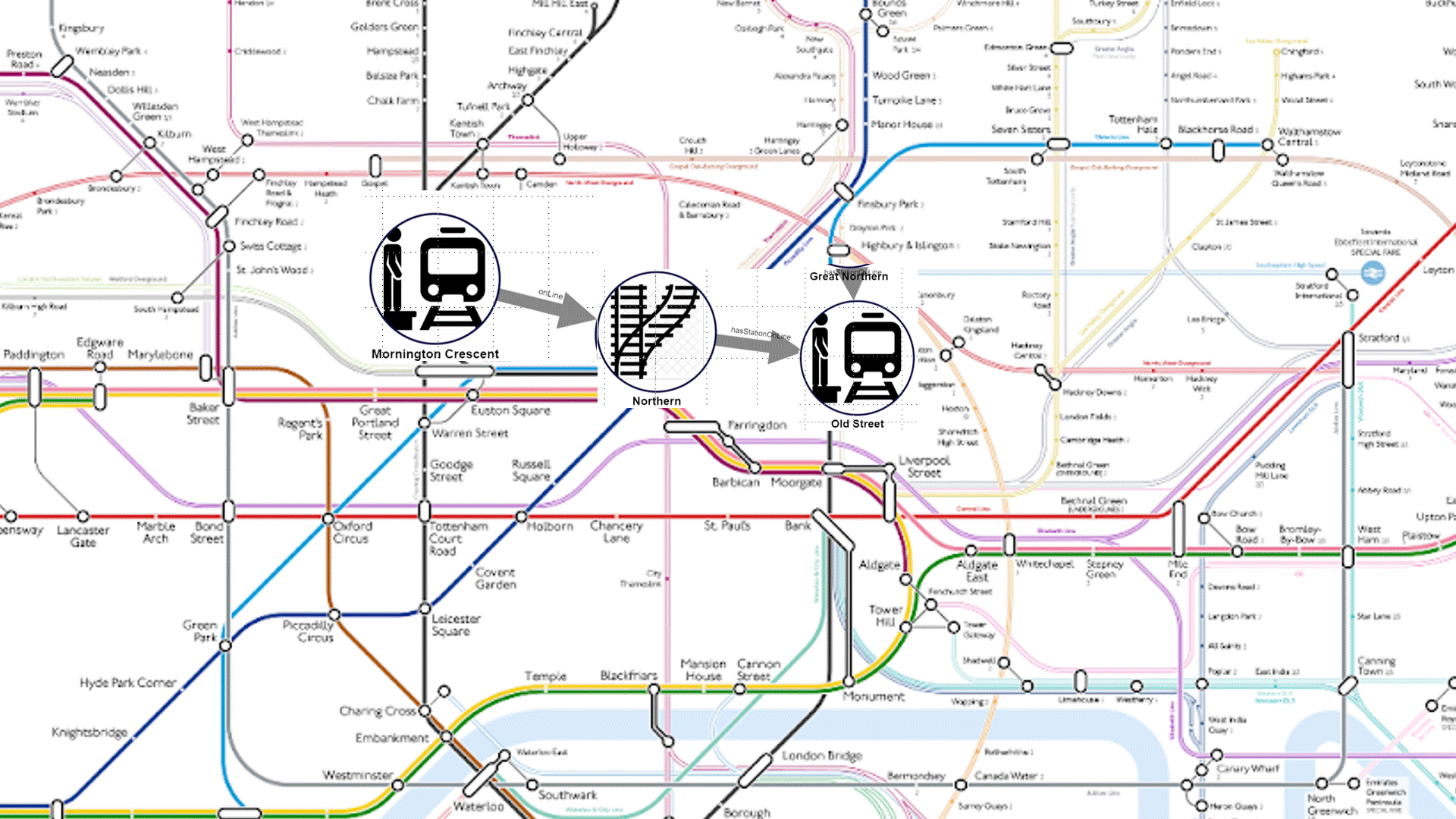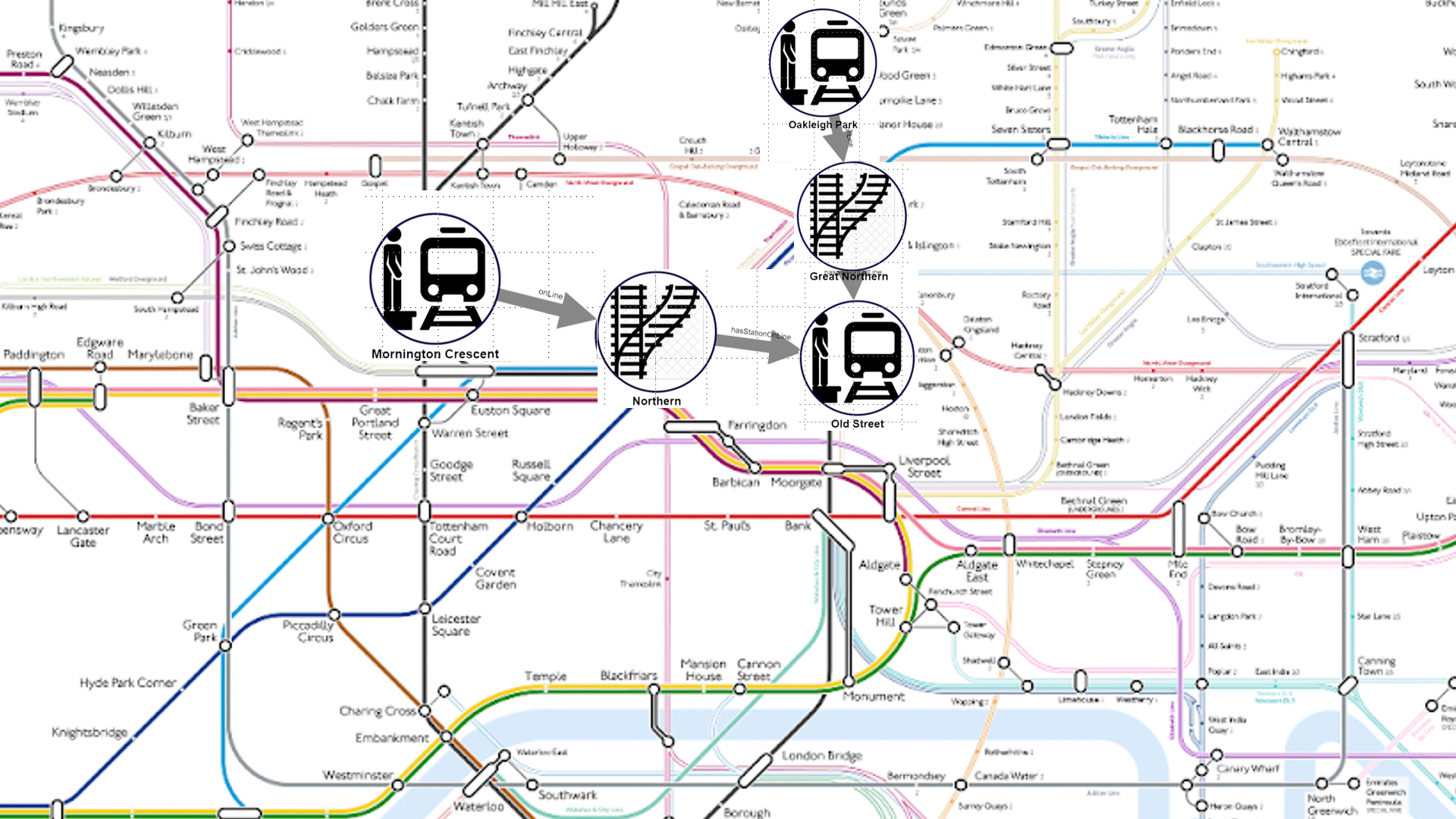
 This pathQL query will return all paths between any data element that is declared as ‘Sensitive’, and any data element of the report that is being validated to ensure that it is not derived from sensitive information.
This pathQL query will return all paths between any data element that is declared as ‘Sensitive’, and any data element of the report that is being validated to ensure that it is not derived from sensitive information. 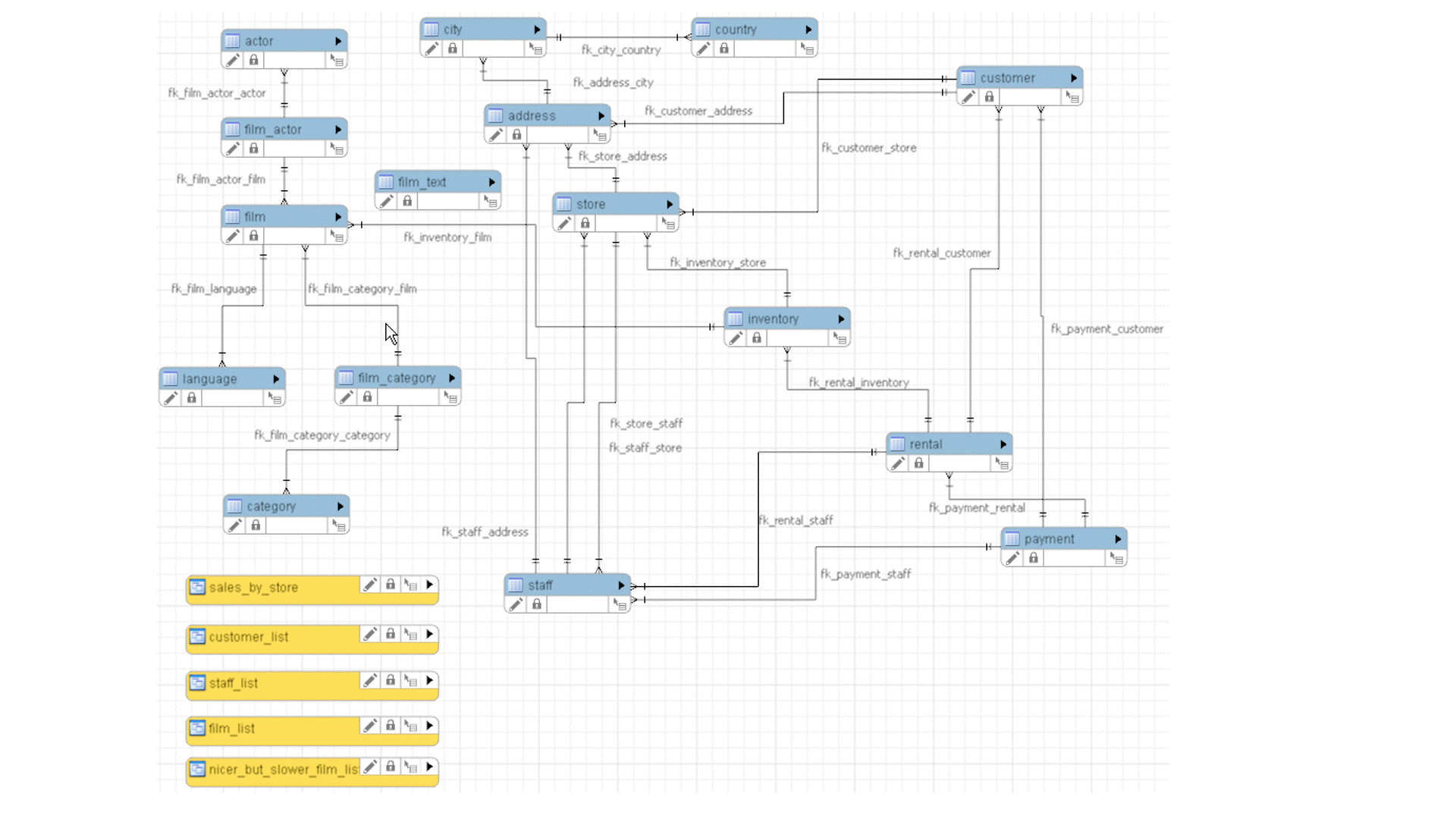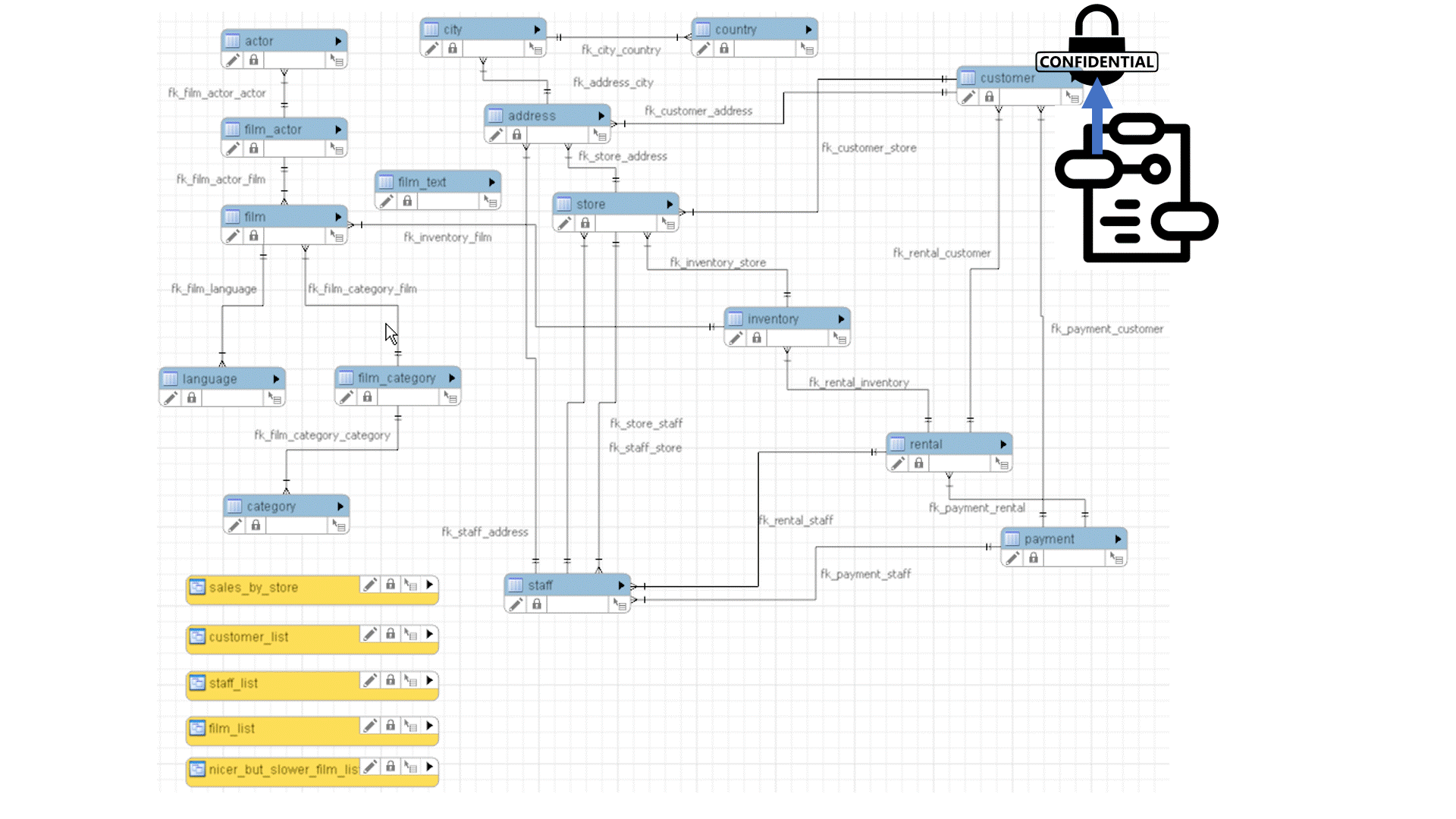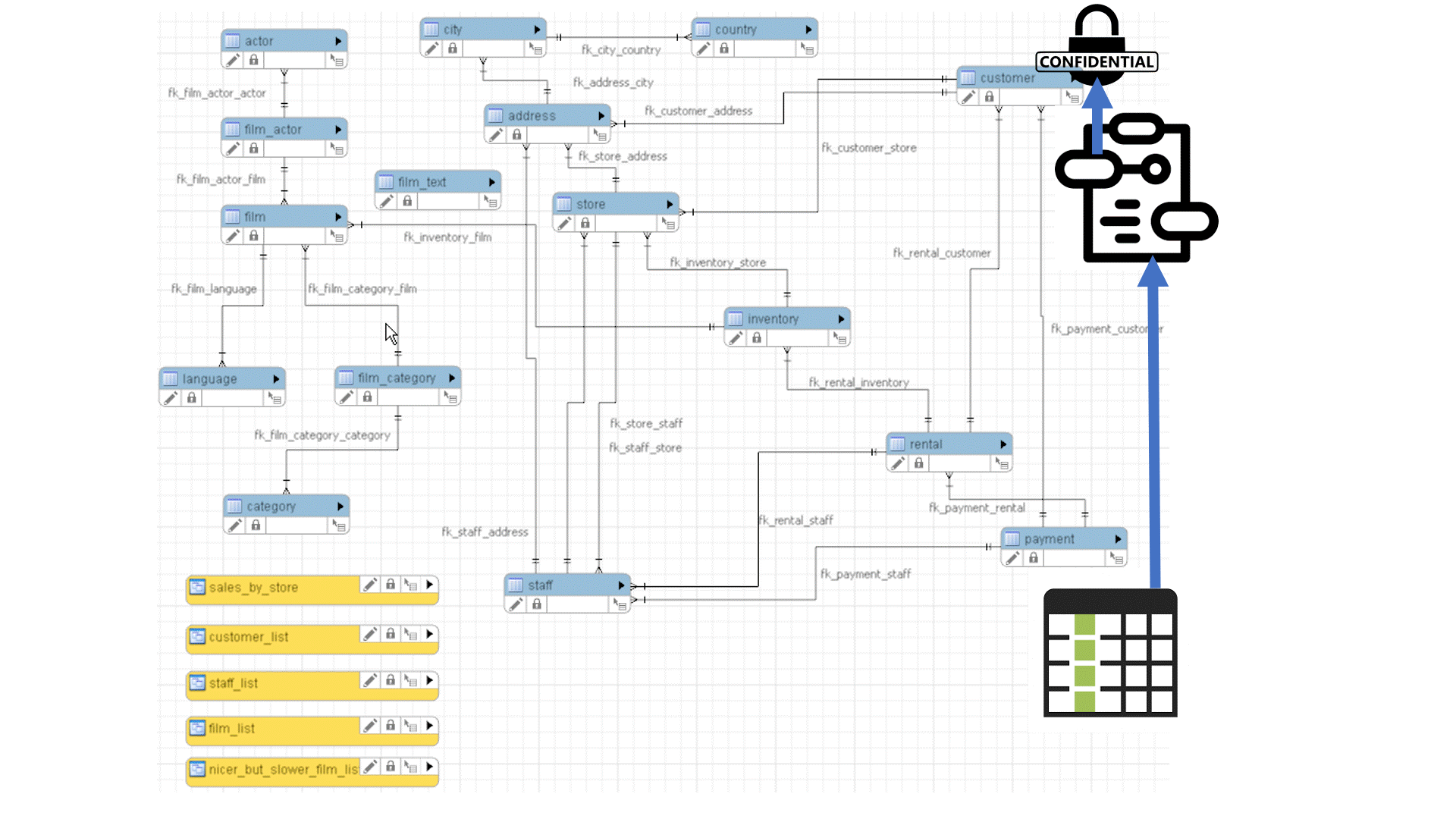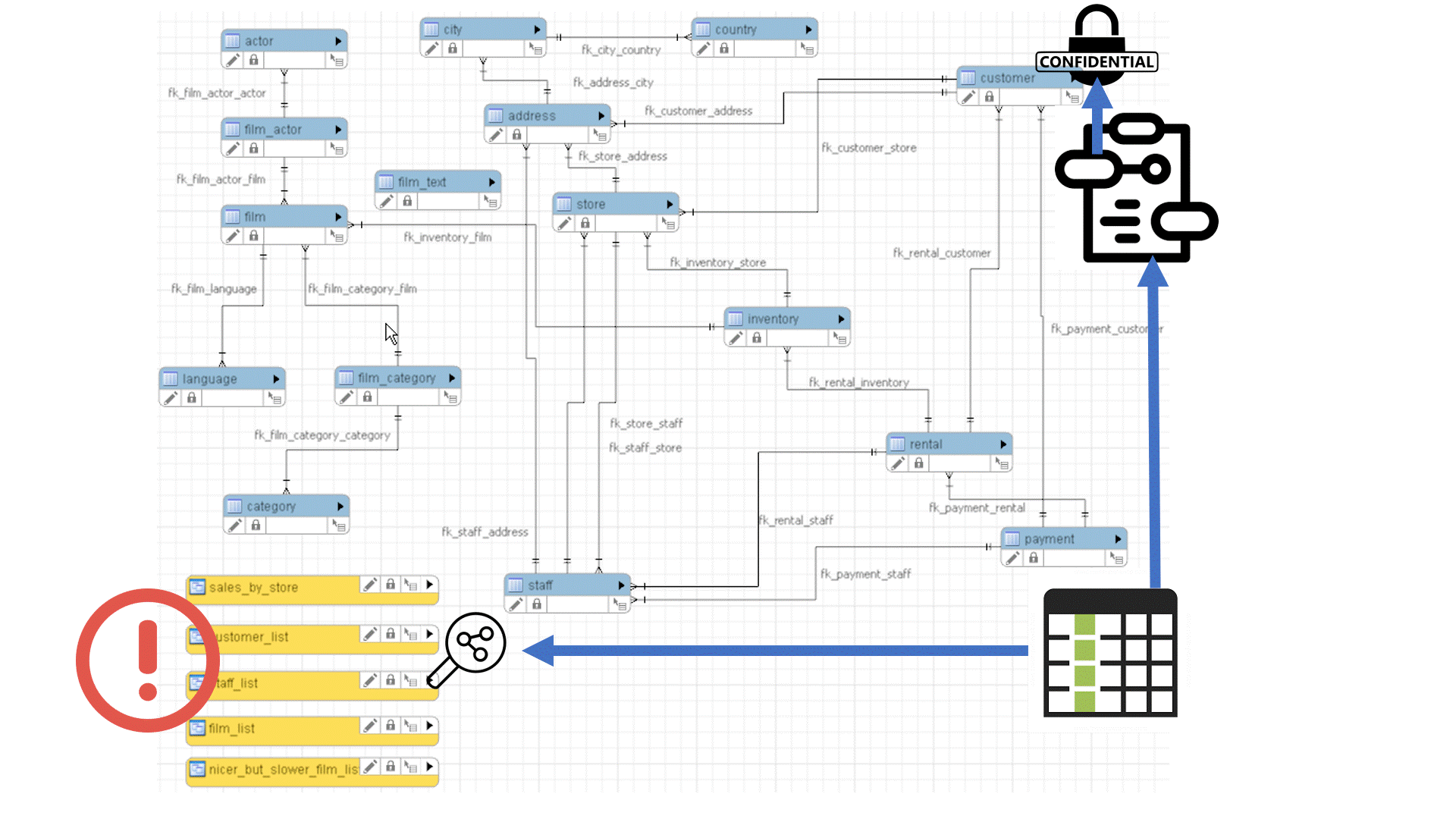
 This pathQL query starts with any individual, in this case, ‘Arnold’, then searches through all immediate and indirect relatives until we encounter the first one that went to Harvard. If we continue to explore the paths, PathQL will return successively more distant connections to Harvard.
This pathQL query starts with any individual, in this case, ‘Arnold’, then searches through all immediate and indirect relatives until we encounter the first one that went to Harvard. If we continue to explore the paths, PathQL will return successively more distant connections to Harvard.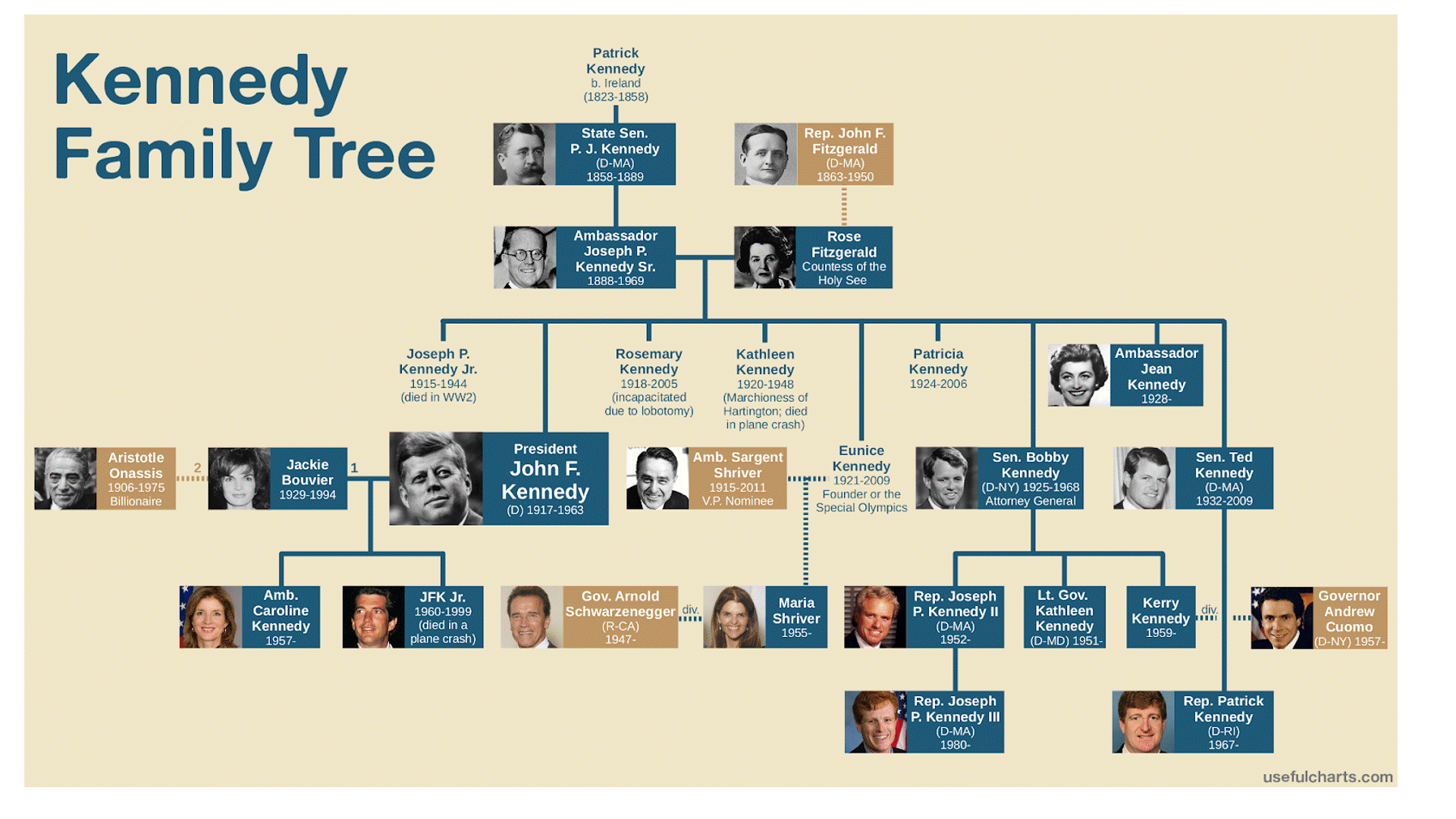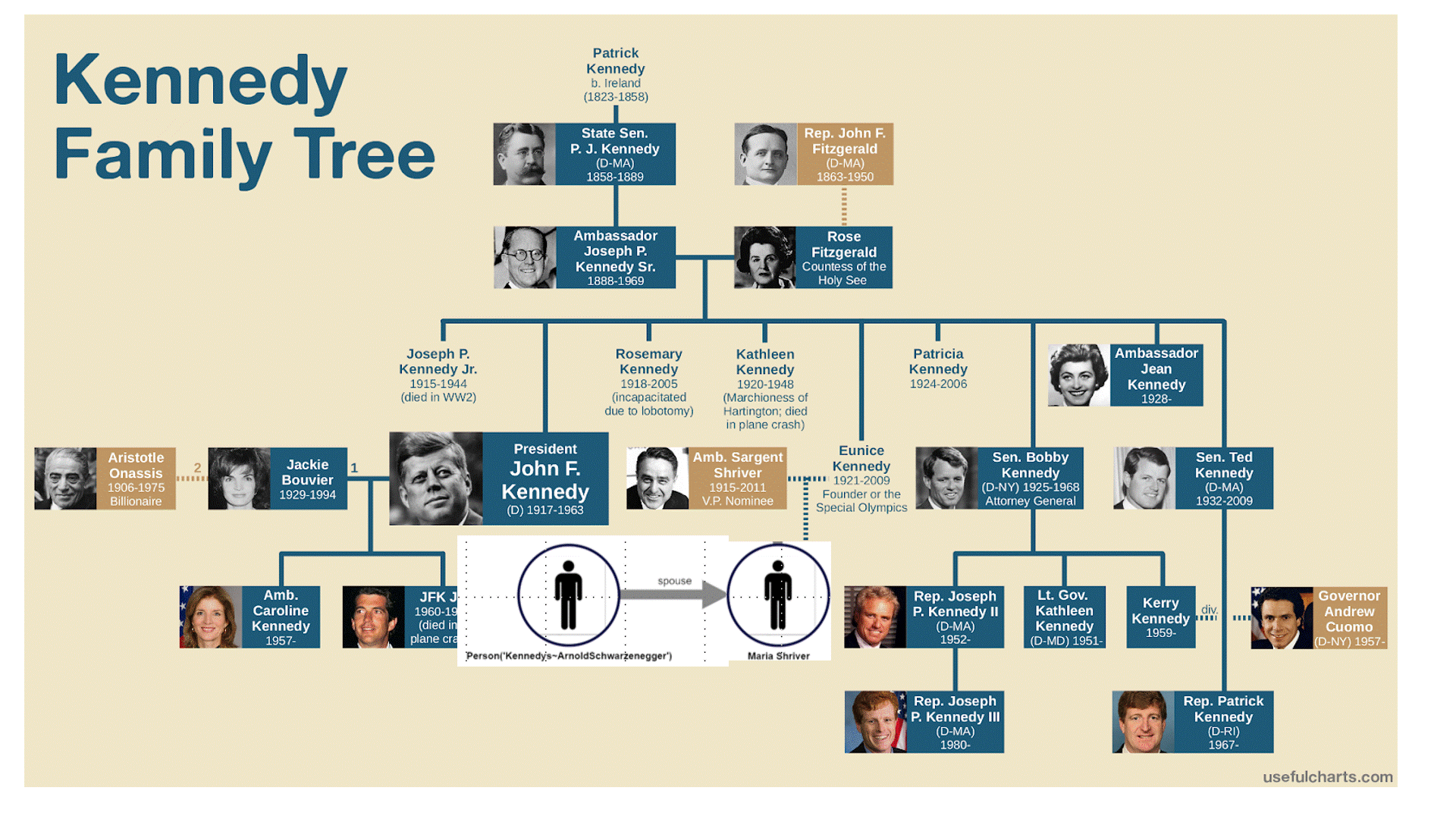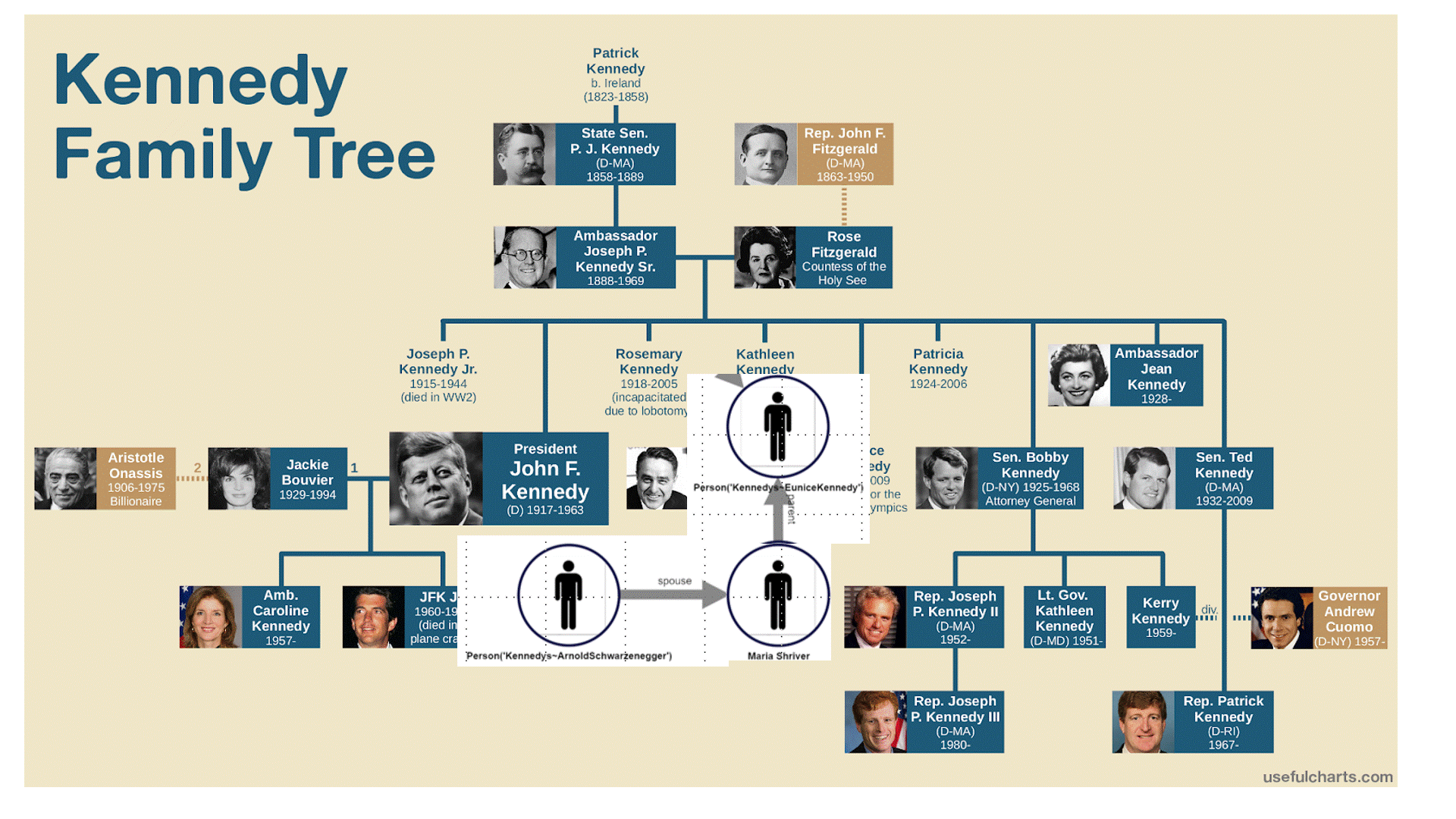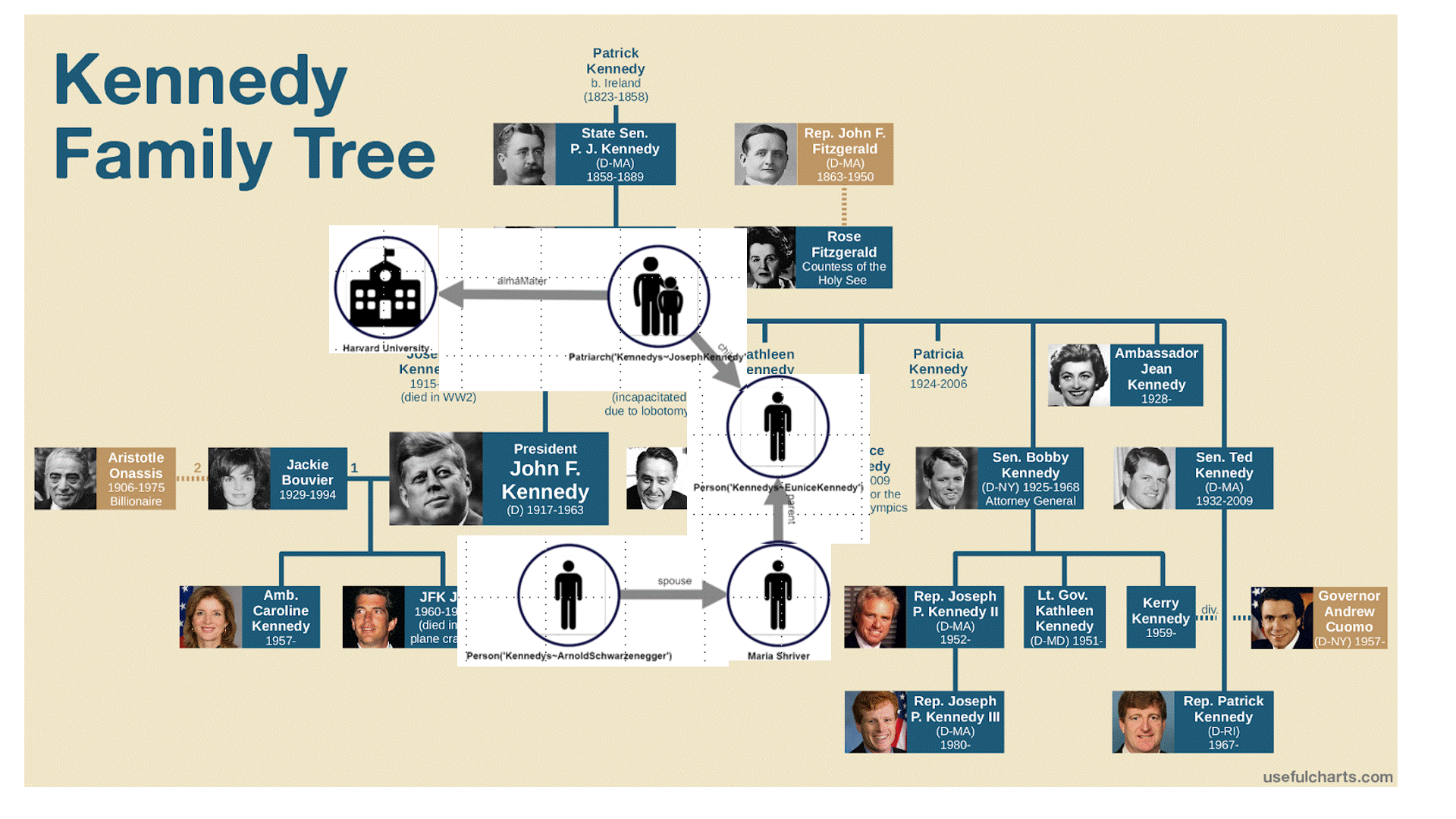
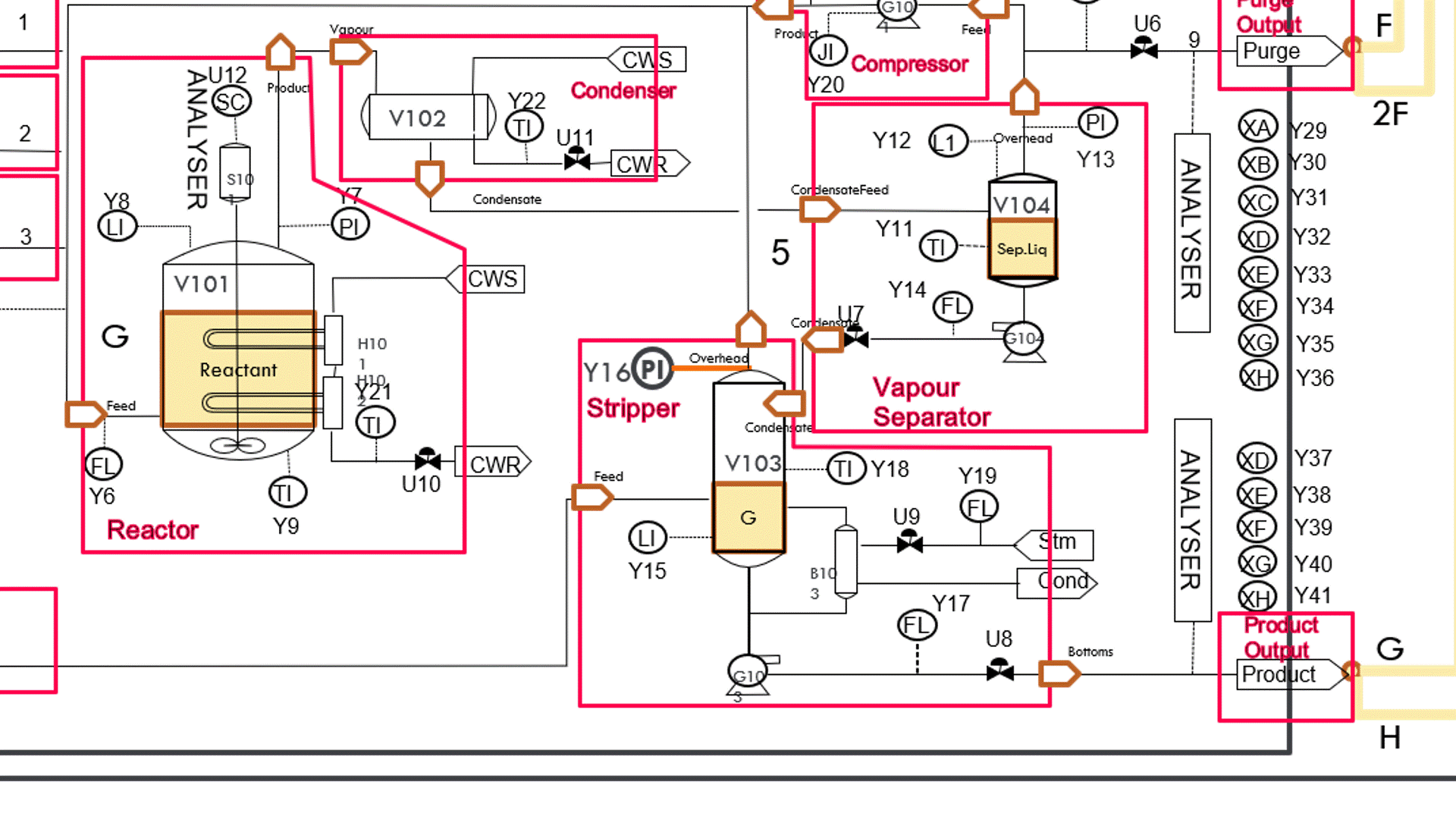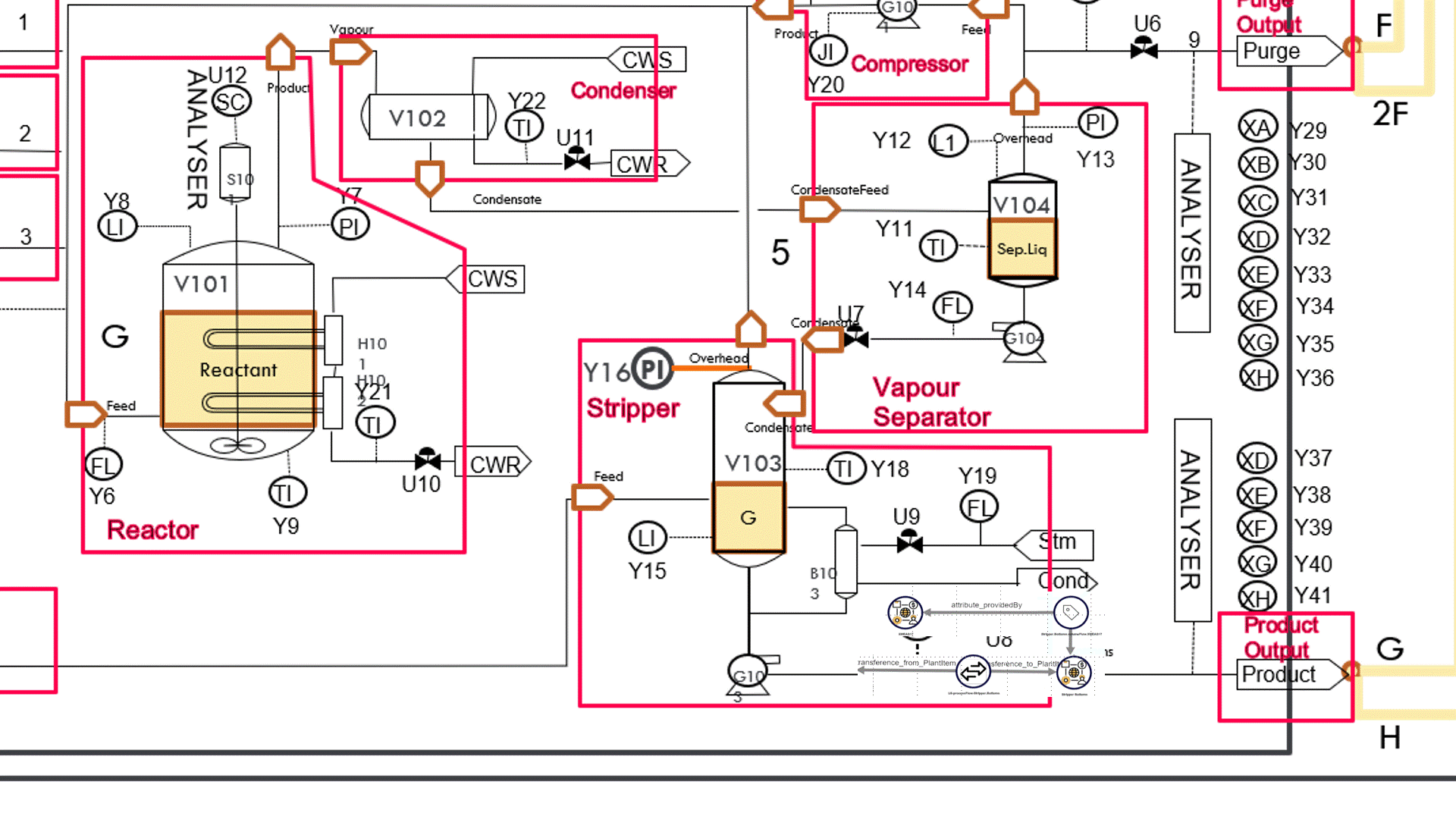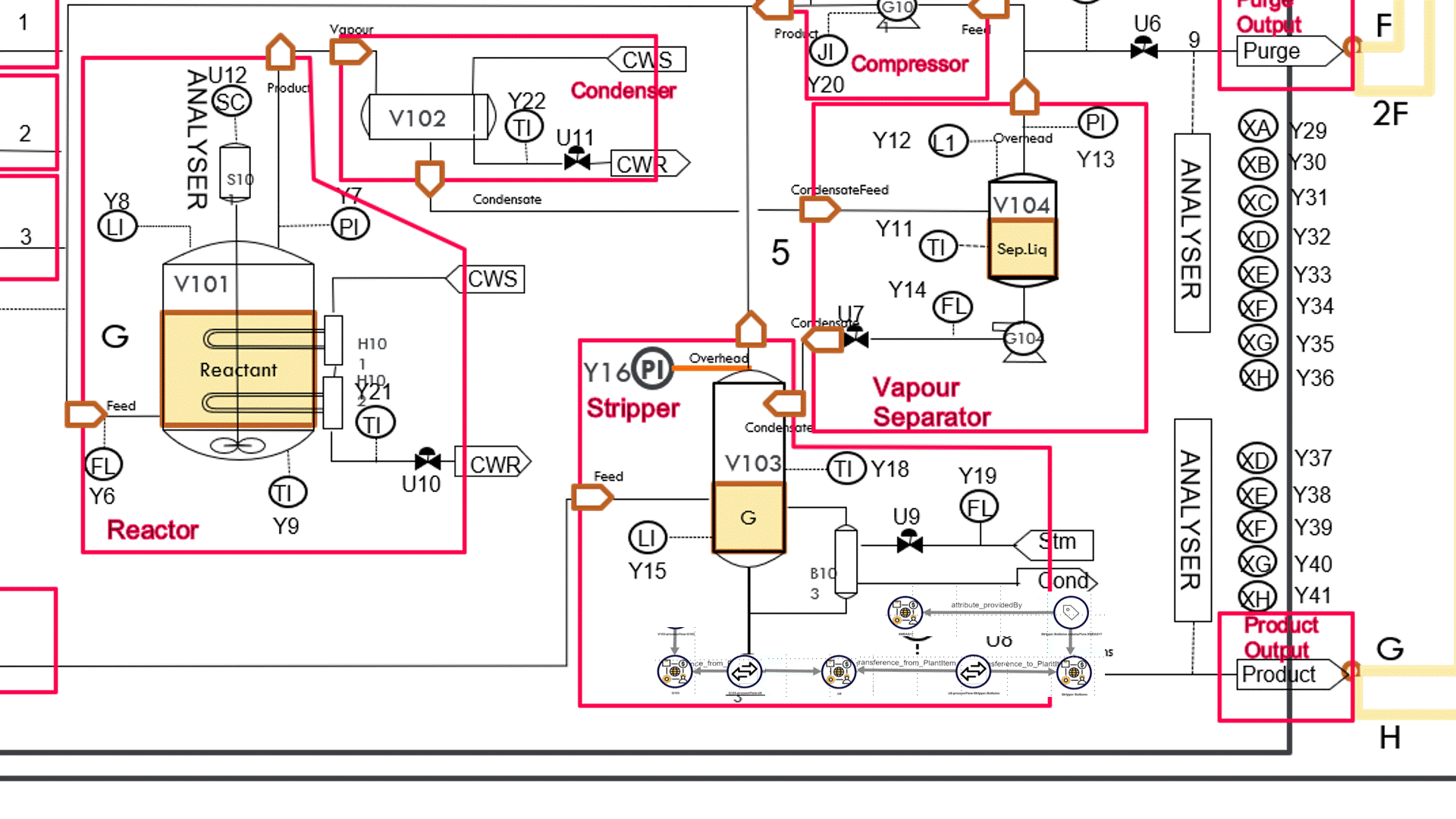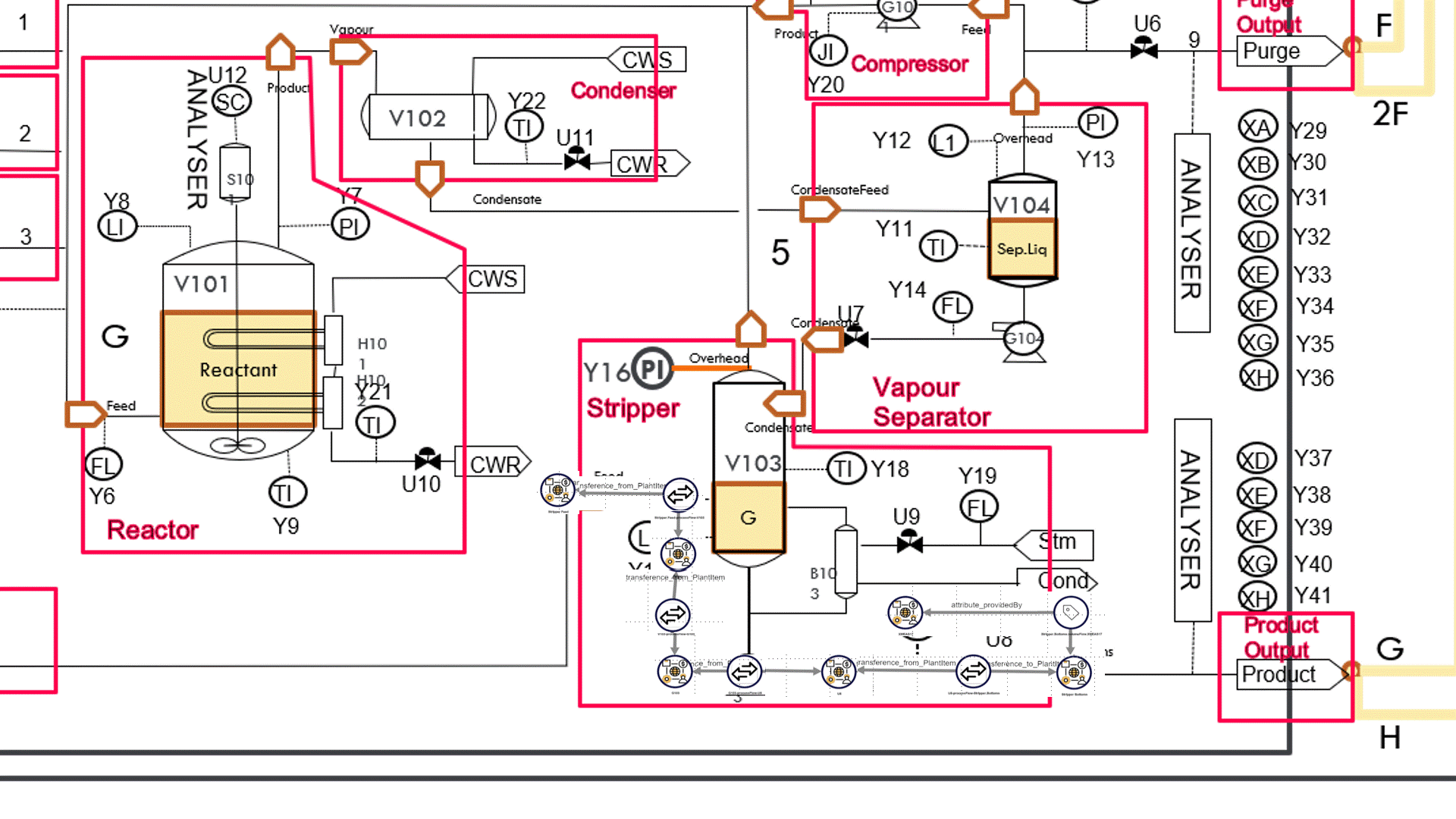
 PathQL can ‘walk’ back through the process flow any number of steps, starting with the plant item with an attribute provided by the out-of-kilter measurement point. As it walks back through the flowsheet, it identifies the attributes of the plant items it encounters, and for each attribute the associated measurement point that serves as the provider of the attribute.
PathQL can ‘walk’ back through the process flow any number of steps, starting with the plant item with an attribute provided by the out-of-kilter measurement point. As it walks back through the flowsheet, it identifies the attributes of the plant items it encounters, and for each attribute the associated measurement point that serves as the provider of the attribute.